

Klasifikasi menggunakan SVM – SVM adalah algoritma supervisi untuk melakukan klasifikasi baik linear maupun nonlinear tergantung pada margin maksimalisasi diantara titik suporrt, mapping data dapat ditransformasi kedalam dimensi yang lebih tinggi. SVM dibangun oleh Vapnik dan Cortes pada 1992, SVM telah sukses diaplikasikan kebanyak kasus seperti pengenalan tulisan tangan, prediksi runtun waktu, pengenalan suara.
Pada tulisan ini akan diberikan mengenai Apa itu SVM, Cara training SVM, Mengukur kinerja nya, Prediksi hasil klasifikasi dengan menggunakan data asing (data yang belum pernah digunakan untuk pelatihan). Karena tulisan ini agak cukup panjang, siapkan waktu yang cukup!
Apa itu Support Vector Machine
Contents
Sebelum melangkah lebih jauh, kalian bisa pelajari fundamental SVM melalui persamaan matematika yang saya bahas disini Fundamental SVM. Disitu dijelaskan mengenai dasar perhitungan SVM menggunakan QP – Quadratic Programming.
Jenis Data
Secara umum jenis data yang akan kita temua ada 2 linear dan non linear seperti gambaran berikut
Linear
Sesuai dengan namanya garis lurus akan tampak dapat dipisahkan hanya dengan sebuah garis lurus untuk membatasi 2 class/kategori
Untuk kasus linear sangat mudah untuk menemukan margin/pembatas seperti berikut

Data Non Linear
Merupakan salah satu jenis data yang sering kita temui dalam dunia nyata, data ini tercipta atas persamaan polinomial

Sedangkan untuk kasus nonlinear, kita butuh teknik hyperplane yaitu transformasi ke dimensi lebih tinggi lagi atau disebut dengan orde R

Inti dari SVM adalah mencoba untuk mencari separating hyperplane alias pembatas secara linear (yang non linear harus dibikin linear dulu)
Tools yang digunakan
Ada banyak tools untuk melakukan mencoba SVM, anda bisa menggunakan matlab dengan function svmclassify ataupun Python dengan pustaka sklearn. Terserah anda karena semua punya kelebihan masing-masing. Disini saya menggunakan Python saja biar lebih mudah, kalau untuk matlab, kalian bisa baca disini Support Vector Machine di Matlab
Persiapan Pustaka/Library
Library yang digunakan yaitu
- Numpy untuk mengolah matrix
- Pandas untuk membaca data struktur
- Matplotlib untuk visualisasi plot
- Sklearn untuk machine learningnya
Juga kita menggunakan Spyder untuk Editornya, cara install semua package, bisa baca buku disini, Buku Belajar Mudah Python dengan Package Open Source
Persiapan Data Linear
Karena penulis suka menggunakan Python, silahkan bagi anda install terlebih dahulu. Siapkan data dalam bentuk excel disimpan dengan nama data linear.xlsx

Visualisasi data dan Implementasi SVM Linear
Data yang digunakan bersifat linear, sehingga persamaan rumus matematikanya seperti berikut
![\[y=a*x+b\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-a7c957fe5f5a5c232ec0c1b3c6a3a41f_l3.png "Rendered by QuickLaTeX.com")
sebagai fungsi linear 2 dimensi.
Bila sudah siap, kita akan langsung saja melakukan ploting
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn import svm
data1 = pd.read_excel('data linear.xlsx')
x1 = data1['p1']
x2 = data1['p2']
x_training = np.array(list(zip(x1,x2)))
y_training = data1['t']
nama_kelas = ['-1','+1']
i_plus = y_training[y_training>0].index
i_min = y_training[y_training<0].index
plt.figure()
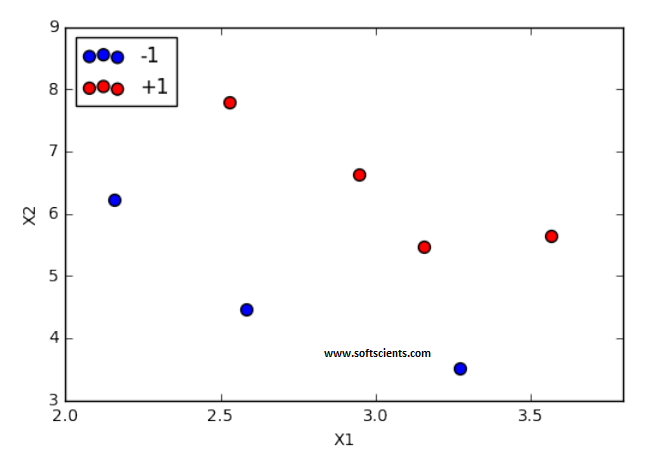
plt.scatter(x_training[i_min,0],x_training[i_min,1],c='b',s=100)
plt.scatter(x_training[i_plus,0],x_training[i_plus,1],c='r',s=100)
plt.legend(nama_kelas)
plt.title('Kasus Linear')
Sengaja saya berikan warna biru untuk minus dan merah untuk plus, Hasilnya seperti berikut

Tugas dari SVM adalah mencari nilai a dan b dari sebuah function linear tersebut diatas. Kita akan menggunakan library sklearn yaitu SVC yang merupakan C-Support Vector Classification berupa implementasi dari library libsvm. Kita lanjut code-nya dengan berikut
svc = svm.SVC(kernel='linear').fit(x_training,y_training)
weight = svc.coef_
intercept = svc.intercept_
a = -weight[0,0] / weight[0,1]
b = -intercept[0]/weight[0,1]
print('y = '+str(a)+' * x + '+str(b)) #fungsi linear
menghasilkan
y = -1.56974382329 * x + 9.95470962319
Sesuai dengan jenis kernel=’linear’. Kita tambahkan code lagi, untuk visualisasi separating line nya, kita coba membuat rentang nilai sumbu x dari 2 sampai 3.8 dengan increment 0.1 seperti berikut
x_coba = np.arange(2,3.8,0.1) y_coba = np.multiply(a,x_coba)+b #penerapan fungsi linear plt.plot(x_coba,y_coba)
Menghasilkan garis biru ditengah sebagai pemisah antara plus dan minus nya.

Melakukan Prediksi Data asing dengan SVM
Bagaimana penggunanan SVM untuk melakukan prediksi data? Misalkan kita mempunyai data berikut

Bila kita plotkan berikut

Terlihat bahwa data asing terletak di area plus, untuk mengujinya cukup gunakan predict()
x_asing = np.array([[3,6]]) print svc.predict(x_asing)
menghasilkan
[1]
Sudah tepat SVM melakukan prediksi data asing yaitu kategori kelas plus
Score SVM
Agar tampak lebih meyakinkan, kita melihat score nya dengan score() dengan score 0.0 – 1 seperti berikut
print svc.score(x_training,y_training)
menghasilkan
1.0
Sehingga dikatakan bahwa SVM melakukan tugasnya 100%. Tulisan akan disambung lagi untuk kasus data non linear yang sering kita jumpai dikehidupan sehari-hari, tapi dengan contoh kasus sederhana terlebih dahulu, ikuti saja serialnya di www.softscients.com
Link Pembahasan Mengenai SVM
- LIBSVM – A Library for Support Vector Machines di GNU Octave
- Support Vector Machine – SVM
- OpenCV di Java SVM Bagian 4
- Modifikasi Kernel Function di SVM
Demikian pembahasan mengenai Klasifikasi menggunakan SVM, bila ada yang kurang jelas, silahkan untuk comment dibawah ini disertai nama dan alamat email