
2,387 Views
Sinopsis
Format currency adalah hal umum yang sering dijumpai dalam pengolahan data berbasis excel karena memudahkan bagi user untuk memisahkan nilai nominal yang besar. Penggunaan format currency yang digunakan oleh Indonesia dan Amerika itu berbeda dalam seperator ribuan dan separator desimal. Misalkan dalam format Currency Amerika untuk nominal sepuluh ribu lima ratus dalam excel ditulis $ 10,500.00 sedangkan dalam format Indonesia Rp 10.500,00. Postingan kali ini membahas pertanyaan email dari pembeli buku saya di buku-belajar-mudah-python. Bagaimana mengolah data dari CSV/Excel yang mempunyai format currency serta menampilkan dalam bentuk grafik serta diberikan keterangan seperti contoh gambar diatas.
Mari kita bahas satu-persatu mulai dari Setting Separator di Excel dilanjutkan Pengolahan Data di Pandas.
Setting Separator di Excel
Aplikasi excel secara default menggunakan separator ribuan/thousand berupa tanda koma (american style) yang berbeda dengan format indonesia, untuk settingnya cukup mudah yaitu File -> Options -> Advanced maka perhatikan options berikut.

Kamu bisa ubah ke format Indonesia yaitu Decimal Separator berupa koma dan thousands separator berupa titik, berikut hasilnya menggunakan excel format indonesia.

Cleaning Up Currency
Kembali pada persoalannya yaitu cleaning up currency atau membersihkan format mata uang menggunakan Pandas dikarenakan didalam excel mempunyai mekanisme encoding yang sangat baik sehingga bila dijumpai seperti berikut.
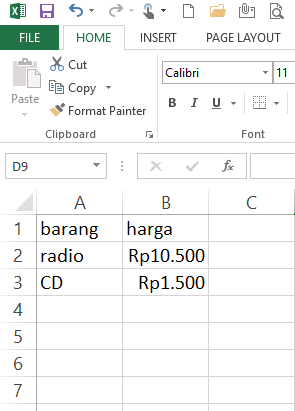
maka library Pandas pun akan menyesuaikan sehingga separator dan simbol mata uang akan dihilangkan

Akan berbeda jika file excel tersebut di export ke CSV ataupun kita mendowload sebuah file berbasis CSV yang mengandung format mata uang seperti berikut.

File diatas adalah hasil download dari www.investing.com untuk saham UNVR periode harian dengan format Indonesia. Bila menggunakan Pandas dengan kode berikut
import pandas as pd file ='Data Historis UNVR.csv' data = pd.read_csv(file) print(data.head()) print(data.dtypes)
Hasilnya akan dianggap sebagai nilai desimal puluhan yang seharusnya bernilai 42.250 atau 42000 hanya bernilai 42.25 saja
Tanggal Terakhir Pembukaan Tertinggi Terendah Vol. Perubahan% 0 06/12/2019 42.250 42.10 42.30 42.00 1,33M 0,24% 1 05/12/2019 42.150 42.00 42.50 42.00 1,00M 0,36% 2 04/12/2019 42.000 42.60 42.60 41.95 1,69M -1,58% 3 03/12/2019 42.675 42.65 42.80 42.10 1,32M -0,41% 4 02/12/2019 42.850 41.80 42.85 41.80 1,98M 2,51% Tanggal object Terakhir float64 Pembukaan float64 Tertinggi float64 Terendah float64 Vol. object Perubahan% object dtype: object
Oleh karena hal tersebut, pada saat read nya perlu dberikan opsi object
import pandas as pd file ='Data Historis UNVR.csv' data = pd.read_csv(file, dtype=object) print(data.head()) print(data.dtypes)
hasilnya
Tanggal Terakhir Pembukaan Tertinggi Terendah Vol. Perubahan% 0 06/12/2019 42.250 42.100 42.300 42.000 1,33M 0,24% 1 05/12/2019 42.150 42.000 42.500 42.000 1,00M 0,36% 2 04/12/2019 42.000 42.600 42.600 41.950 1,69M -1,58% 3 03/12/2019 42.675 42.650 42.800 42.100 1,32M -0,41% 4 02/12/2019 42.850 41.800 42.850 41.800 1,98M 2,51% Tanggal object Terakhir object Pembukaan object Tertinggi object Terendah object Vol. object Perubahan% object dtype: object
Kemudian lakukan replace yaitu menghilangkan tanda titik pada Kolom Terakhir; Pembukaan; Tertinggi; dan Terendah serta mengubahnya dari object kedalam double sehingga kita bisa membuat plot grafik untuk harga Terakhir serta Mean nya.

import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file ='Data Historis UNVR.csv'
data = pd.read_csv(file,dtype=object)
print(data.head())
keterangan_y = list(data['Terakhir'])
data['Terakhir']=data['Terakhir'].str.replace('.','')
data['Pembukaan']=data['Pembukaan'].str.replace('.','')
data['Tertinggi']=data['Tertinggi'].str.replace('.','')
data['Terendah']=data['Terendah'].str.replace('.','')
rerata = np.mean(np.array(data['Terakhir'],dtype=np.double))
rerata = np.ones([len(data['Terakhir'])])*rerata
print(data.head())
fig, ax = plt.subplots(1,1)
ax.plot(np.array(data['Terakhir'],dtype=np.double))
ax.plot(rerata)
# Set ticks labels for x-axis
ax.set_xticklabels(list(data['Tanggal']), rotation=45, fontsize=12)
ax.set_yticklabels(keterangan_y, rotation=0, fontsize=12)
ax.grid('on')
ax.legend(['Harga Terakhir','Rerata'])
ax.set_xlabel('Tanggal dd/mm/yyyy')
ax.set_ylabel('Harga Rp.')
ax.set_title('Harga Saham UNVR Harian')
Hasil akan tampil sebagai berikut
Tanggal Terakhir Pembukaan Tertinggi Terendah Vol. Perubahan%
0 06/12/2019 42.250 42.100 42.300 42.000 1,33M 0,24%
1 05/12/2019 42.150 42.000 42.500 42.000 1,00M 0,36%
2 04/12/2019 42.000 42.600 42.600 41.950 1,69M -1,58%
3 03/12/2019 42.675 42.650 42.800 42.100 1,32M -0,41%
4 02/12/2019 42.850 41.800 42.850 41.800 1,98M 2,51%
Tanggal Terakhir Pembukaan Tertinggi Terendah Vol. Perubahan%
0 06/12/2019 42250 42100 42300 42000 1,33M 0,24%
1 05/12/2019 42150 42000 42500 42000 1,00M 0,36%
2 04/12/2019 42000 42600 42600 41950 1,69M -1,58%
3 03/12/2019 42675 42650 42800 42100 1,32M -0,41%
4 02/12/2019 42850 41800 42850 41800 1,98M 2,51%
Sehingga kunci replace() dapat digunakan untuk keperluan yang lainnya bila kamu inginkan sesuai dengan kasus yang kamu temui.