
Sinopsis
Contents
- 1 Sinopsis
- 2 Jumlah Keseluruhan / SUM
- 3 Rata-Rata Aritmatik atau Rata-Rata Hitung
- 4 Modus
- 5 Median
- 6 Range
- 7 Variance
- 8 Standar Deviasi
- 9 Koefisien Variasi
- 10 Data yang dibakukan (data standarisasi)
- 11 Ukuran Kemiringan Distribusi Data (skewness)
- 12 Ukuran Keruncingan (kurtosis)
- 13 Package psych
- 14 Package Pastecs
Sebagai pembahasan dasar-dasar statistika, kalian akan belajar yang dimulai dari mengukur gejala pusat seperti sum, mean, median, variance, standar deviasi dan yang lainnya. Hal ini berguna sebagai deskripsi awal mengenai datasetnya sehingga mampu menggunakan tools analisis yang lainnya. Pembahasan ini secara garis besar dibagi menjadi 2 yaitu
- Diberikan pengertian dan rumus matematika setiap operasi statistik dasar dengan R Serta membuat function dalam kode R.
- Menggunakan package untuk melakukan operasi statistika. Oiya jangan lupa kalian belajar plot grafik dan cara install package di R
Sebagian besar dataset yang digunakan menggunakan format CSV yang diload kedalam Data Frame ataupun dalam bentuk vector untuk mempermudah dalam pengolahan selanjutnya. Sebagai contoh terdapat dataset berikut.

Berdasarkan tabel diatas akan dihitung sum, mean, modus, dan medianya yang disajikan dalam bentuk variabel vector di R
nilai_siswa<-c(8,9,7,8,6,7)
Jumlah Keseluruhan / SUM
Jika kita mempunyai data  . Simbol untuk menentukan nilai keseluruhan yaitu
. Simbol untuk menentukan nilai keseluruhan yaitu
![\[total = \sum_{i-1}^{n}X_i\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-07cff997ec390ad83d6e7308c7059422_l3.png "Rendered by QuickLaTeX.com")
Perintah yang digunakan yaitu 
sum(nilai_siswa)
hasil
45
Rata-Rata Aritmatik atau Rata-Rata Hitung
Merupakan jumlah seluruh nilai dari data, dibagi dengan banyaknya data. Berikut rumus untuk menghitung nilai rata-rata aritmatik (sampel)
![\[\bar{X}=\frac{\sum_{i=1}^{n}X_i}{n}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-68e5f2fd4943fbb77beb7623cd8c94ed_l3.png "Rendered by QuickLaTeX.com")
Gunakan perintah 
mean(nilai_siswa)
hasil
7.5
Modus
Modus jangan disalahartikan dengan motifasi (konotasi jelek) tapi merupakan nilai dengan frekuensi terbesar, untuk dataset diatas yaitu 8 karena muncul sebanyak 2 kali. Sayangnya didalam R tidak punya function built in sehingga kalian bisa membuat function tersendiri untuk mencari nilai modus.
modus <- function(x) {
ux <- unique(x)
return (ux[which.max(tabulate(match(x, ux)))])
}
modus(nilai_siswa)
hasil
8
Median
Nilai tengah Nilai dari median membagi data menjadi dua bagian yang sama dengan cara terlebih dahulu diurutkan dari yang terkecil hingga yang terbesar, untuk dataset diatas menghasilkan nilai 7.5; Perintah yang digunakan 
median(nilai_siswa)
Selain nilai sum, mean, median ada hal lain yang perlu kalian ketahui seperti nilai sebaran. Perhatikan tabel berikut yang mempunyai nilai mean sama yaitu 7.5

Ukuran pencaran yang akan dipaparkan dalam tulisan ini adalah range, variance, dan standar deviasi. Untuk dataset diatas, kita ubah saja dalam bentuk data frame seperti berikut
A<-c(8, 9, 7, 8, 6, 7) B<-c(5, 9, 9, 9, 6, 7) C<-c(10, 4, 4, 9, 9, 9) nilai<-data.frame(A,B,C)
Range
Range merupakan selisih antara nilai maksimum dengan nilai minimum, perintah yang digunakan yaitu  yang akan mengembalikan 2 nilai sekaligus yaitu minimal dan maksimal dalam bentuk vector.
yang akan mengembalikan 2 nilai sekaligus yaitu minimal dan maksimal dalam bentuk vector.
range(nilai$A) range(nilai$B) range(nilai$C)
hasil
> range(nilai$A) [1] 6 9 > range(nilai$B) [1] 5 9 > range(nilai$C) [1] 4 10
Variance
Variance berhubungan erat dengan standard deviation, yaitu digunakan untuk mengukur dan mengetahui seberapa jauh bagaimana penyebaran data dalam distribusi data. Dengan kata lain digunakan untuk mengukur variabilitas data
Dalam bahasa awam variance adalah untuk mengetahui tingkat keragaman dalam data. Semakin tinggi nilai variance berarti semakin bervariasi dan beragam suatu data. Untuk menghitung variance, harus diketahui terlebih dahulu mean-nya, kemudian menjumlahkan kuadrat selisih dari tiap-tiap data terhadap mean tersebut. Secara numeric, variance merupakan rata-rata dari kuadrat selisih data terhadap mean.
Variance (dalam hal ini variance untuk sampel) dilambangkan dengan  . Berikut rumus untuk menghitung nilai variance.
. Berikut rumus untuk menghitung nilai variance.
![\[S^2 = \frac{|X-\bar{X}|^2}{n-1}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-9f0c4436603794f80c737f840806a301_l3.png "Rendered by QuickLaTeX.com")
Perintah yang digunakan yaitu 
var(nilai_siswa)
hasil
1.1
Standar Deviasi
Standard deviation diperoleh dari akar dari variance dan digunakan untuk mengukur penyebaran data. Standar deviasi merupakan akar kuadrat positif variance. Nilai dari standar deviasi dapat diinterpretasi sebagai nilai yang menunjukkan seberapa dekat nilai-nilai data menyebar atau berkumpul di sekitar rata-ratanya. Standar deviasi merupakan salah satu dari ukuran pencaran yang paling sering digunakan.
![\[\sqrt{S^2}= S\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-925ab4b07450803ceda124899826295b_l3.png "Rendered by QuickLaTeX.com")
Perintah yang digunakan yaitu 
sd(nilai_siswa)
hasil
1.048809
Koefisien Variasi
Kalian bisa lihat dataset berikut yang mempunyai range nilai yang berbeda, untuk kelas A mempunyai range nilai 0 sd. 10; untuk kelas B mempunyai range nilai 0 s.d 100; sedangkan untuk kelas C mempunyai range nilai 0 s.d 1. Misalkan untuk menggambarkan heterogen mana antara kelas A, B, dan C
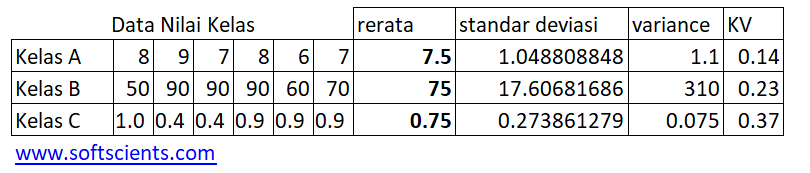
Untuk itu dapat digunakan koefisien variasi untuk membandingkan tingkat variasi atau heterogen di antara dua atau lebih kelompok ketika suatu satuan/range nya berbeda-beda dengan rumus
![\[KV=\frac{s}{\bar{X}}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-90a05382fd55a32ece8e9e74941b9b61_l3.png "Rendered by QuickLaTeX.com")
Kode
kv<-function(x){
return (sd(x)/mean(x))
}
A<-c(8, 9, 7, 8, 6, 7)
B<-c(5, 9, 9, 9, 6, 7)
C<-c(10, 4, 4, 9, 9, 9)
B<-B*10
C<-C/10
kv(nilai$A)
kv(nilai$B)
kv(nilai$C)
hasil
> kv(nilai$A) [1] 0.1398412 > kv(nilai$B) [1] 0.2347576 > kv(nilai$C) [1] 0.3651484
Semakin tinggi nilai koefisen variasi maka makin heterogen.
Data yang dibakukan (data standarisasi)
Variabel yang mengukur deviasi dari rerata dalam unit disebut dengan variabel yang dibakukan. Rumus umumnya yaitu
![\[z=\frac{X-\bar{X}}{s}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-5b334581688dcc3a6791105560684f4b_l3.png "Rendered by QuickLaTeX.com")

Perhatikan nilai Z baku diatas harus mempunyai nilai rerata 1 dan standar deviasi 0. Berdasarkan uraian tersebut, data dalam bentuk standar atau baku sangat berguna untuk tujuan perbandingan distribusi dari beberapa kelompok data. Untuk kode dalam R kalian bisa menggunakan sebuah library saja atau menggunakan function berikut
zdata<-function(x){
return ((x-mean(x))/sd(x))
}
A<-c(8, 9, 7, 8, 6, 7)
z<-zdata(A)
print(data.frame(A,z))
hasi
A z 1 8 0.4767313 2 9 1.4301939 3 7 -0.4767313 4 8 0.4767313 5 6 -1.4301939 6 7 -0.4767313
Ukuran Kemiringan Distribusi Data (skewness)
Ukuran kemiringan atau skewness merupakan suatu nilai yang mengukur ketidaksimetrisan distribusi data. Suatu data dikatakan berdistribusi simetris sempurna bila nilai rata-rata, median, dan modus dalam data adalah sama.
![\[skewness=\frac{n}{(n-1)(n-2)}(\frac{\sum(X-\bar{X})^3}{s^3})\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-2d0e67d97673d6e5c69eab691347cbf1_l3.png "Rendered by QuickLaTeX.com")

Bila nilai kemiringan < 0 atau negatif, maka kurva cenderung condong ke kiri (kurva negatif). Jika nilai kemiringan > 0 atau positif, maka kurva cenderung condong ke kanan (kurva positif). Jika nilai kemiringan mendekati 0 atau 0, maka kurva cenderung simetris. Oiya untuk perhitungan skewness harus menggunakan frekuensi ya! Misalkan kita punya data berikut dalam bentuk data frame dari sebuah file data skew.csv
No A 1 1 1 2 2 1 3 3 2 4 4 2 5 5 2 6 6 2 7 7 2 8 8 2 9 9 2 10 10 3 11 11 3 12 12 3 13 13 3 14 14 3 15 15 4 16 16 4 17 17 4 18 18 4 19 19 5 20 20 5 21 21 5 22 22 6 23 23 6 24 24 7
Kode yang digunakan untuk menampilkan dan menghitung skew
skew<-function(x){
n<-length(x)
hasil = (n/((n-1)*(n-2)))*(sum((x-mean(x))^3)/sd(x)^3)
return (hasil)
}
#loading data
data_skew = read.csv('data skew.csv')
#hitung skewness
sk<-skew(data_skew$A)
#hitung frekuensi
frekuensi = as.data.frame(table(data_skew$A))
#tampilkan dalam bar plot
barplot(frekuensi$Freq,main=paste('Nilai skew ',sk,sep=': '))

Akan mendekati 0 karena lebih condong kekanan karen nilai nya positif, misalkan lain seperti grafik berikut yang cenderung ke kiri

Lebih jelasnya mengenai menceng kiri dan kanan bila digabungkan yaitu (jangan salah baca baca, menceng kiri jika turunannya arah ke kiri, sebaliknya kalau menceng ke kanan karena turunanya arah ke kanan)

Ukuran Keruncingan (kurtosis)
Ukuran keruncingan atau kurtosis merupakan suatu nilai yang mengukur tingkat keruncingan atau ketinggian puncak dari distribusi data dengan rumusnya yaitu
![\[kurtosis=(\frac{n(n+1)\sum{(X-\bar{X})^2}}{(n-1)(n-2)(n-3)s^4})-\frac{3(n-1)^2}{(n-)(n-3)}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-f782ee0506bb9c1578f2fb90008ad58f_l3.png "Rendered by QuickLaTeX.com")

Semakin tinggi nilai kurtosis, maka semakin runcing, misalkan kita punya dataset berikut
> nilai No A B C 1 1 1 1 1 2 2 1 1 1 3 3 1 1 2 4 4 1 2 2 5 5 2 2 2 6 6 2 2 2 7 7 2 2 2 8 8 2 2 2 9 9 3 2 2 10 10 3 3 2 11 11 3 3 3 12 12 3 3 3
Mempunyai grafik distribusi dan nilai kurtosis sebagai berikut

freq<-function(x){
frekuensi = as.data.frame(table(x))
return (frekuensi$Freq)
}
kurto<-function(x){
n = length(x)
a = n*(n+1)*sum((x-mean(x))^4)
b = (n-1)*(n-2)*(n-3)*sd(x)^4
c = 3*(n-1)^2
d = (n-2)*(n-3)
return ((a/b)-(c/d))
}
#loading data
nilai<-read.csv('data kurtosis.csv')
print(nilai)
kurtoA<-kurto(nilai$A)
kurtoB<-kurto(nilai$B)
kurtoC<-kurto(nilai$C)
par(mfrow= c(1,3))
barplot(freq(nilai$A),main=paste('Nilai kurtosis',kurtoA,sep=': '))
barplot(freq(nilai$B),main=paste('Nilai kurtosis ',kurtoB,sep=': '))
barplot(freq(nilai$C),main=paste('Nilai kurtosis ',kurtoC,sep=': '))
Grafik no 3 mempunyai keruncingan tertinggi dengan nilai 0.73
Package psych
Setelah kalian pelajari agak ribet karena harus membuat function tersendiri karena di R belum tentu ada, tapi tenang saja kalian bisa memanfaatkan package psych hanya dengan perintah describe saja sudah didapatkan banyak informasi mengenai sebuah dataset. Seperti biasanya kalian harus install terlebih dahulu package dengan perintah
install.packages('psych')
Kemudian panggil dengan perintah
library(psych)
Misalkan untuk data berikut
> nilai No A B C 1 1 1 1 1 2 2 1 1 1 3 3 1 1 2 4 4 1 2 2 5 5 2 2 2 6 6 2 2 2 7 7 2 2 2 8 8 2 2 2 9 9 3 2 2 10 10 3 3 2 11 11 3 3 3 12 12 3 3 3
dengan memanggil perintah describe akan didapatkan informasi yang lengkap mengenai data tersebut
describe(nilai)
hasil
vars n mean sd median trimmed mad min max range skew kurtosis se No 1 12 6.5 3.61 6.5 6.5 4.45 1 12 11 0 -1.50 1.04 A 2 12 2.0 0.85 2.0 2.0 1.48 1 3 2 0 -1.74 0.25 B 3 12 2.0 0.74 2.0 2.0 0.74 1 3 2 0 -1.32 0.21 C 4 12 2.0 0.60 2.0 2.0 0.00 1 3 2 0 -0.48 0.17
Fungsi describe dalam hal ini digunakan untuk menentukan
- banyaknya data (n),
- rata-rata aritmatik (mean),
- standar deviasi (sd), median,
- minimum (min),
- maksimum (max),
- range, kemiringan (skew), dan
- kurtosis.
Tapi ada yang kurang sih yaitu nilai variance, sum, dan standard error mean belum dan koefisien korelasi maka kalian perlu install package pastecs
Package Pastecs
Seperti biasa lakukan dulu install package dengan perintah berikut
install.packages('pastecs')
lakukan loading package dengan perintah
library(pastecs)
Perintah yang digunakan yaitu stat.desc()
stat.desc(nilai)
hasilnya
No A B C nbr.val 12.0000000 12.0000000 12.0000000 12.0000000 nbr.null 0.0000000 0.0000000 0.0000000 0.0000000 nbr.na 0.0000000 0.0000000 0.0000000 0.0000000 min 1.0000000 1.0000000 1.0000000 1.0000000 max 12.0000000 3.0000000 3.0000000 3.0000000 range 11.0000000 2.0000000 2.0000000 2.0000000 sum 78.0000000 24.0000000 24.0000000 24.0000000 median 6.5000000 2.0000000 2.0000000 2.0000000 mean 6.5000000 2.0000000 2.0000000 2.0000000 SE.mean 1.0408330 0.2461830 0.2132007 0.1740777 CI.mean.0.95 2.2908580 0.5418451 0.4692516 0.3831423 var 13.0000000 0.7272727 0.5454545 0.3636364 std.dev 3.6055513 0.8528029 0.7385489 0.6030227 coef.var 0.5547002 0.4264014 0.3692745 0.3015113