
Sinopsis
Contents
Analisis cluster atau clustering yaitu suatu teknik yang digunakan untuk mengelompokkan (group) sekumpulan objek ke dalam beberapa cluster. Perhatikan bahwa suatu objek hanya bisa masuk atau tergabung dalam satu cluster. Beberapa objek yang berada dalam satu cluster cenderung saling mirip, namun cenderung berbeda terhadap objek-objek yang berada dalam cluster lainnya.
Metode Clustering
Secara umum clustering dapat dibagi menjadi 2 yaitu
- class not-determined jumlah cluster belum atau tidak diketahui sebelumnya disebut dengan hierarchical
- dan class determined jumlah cluster ditetapkan terlebih dahulu, sebelum melakukan pengclusteran objek disebut non-hierarchical
Lebih lanjut kalian bisa pelajari diagram berikut

Package yang digunakan untuk Analisis cluster
Metode yang akan kita gunakan dalam pembahasan ini untuk fokus pada penggunaan algoritma Kmeans serta menentukan berapa jumlah kluster yang optimal? Nah untuk hal tersebut kita membutuhkan 4 package yaitu tidyverse, cluster dan factoextra serta dplyr yang harus kalian install package di R terlebih dahulu dengan perintah seperti biasa yaitu
install.packages(‘dplyr’) install.packages(‘tidyverse’) install.packages(‘cluster’) install.packages(‘factoextra’)
Oiya, jika kalian install package factoextra maka akan secara otomatis install ggplot2 yang merupakan plot visualisasi yang sangat bagus. Serta jangan lupa untuk loading package tersebut
library(dplyr) #data frame library(tidyverse) # library(cluster) # Algoritma clustering library(factoextra) # Algoritma clustering dan visualisasi library(ggplot2) # grafik
Dataset
Dataset yang digunakan merupakan pengukuran sebuah buah yang diukur suhu dan beratnya yang disimpan dengan sebaran.csv. Untuk loading menggunakan perintah berikut
suhu berat 1 7 8 2 4 13 3 8 7 4 8 9 5 3 12 6 3 1 7 5 3 8 3 13 9 9 8 10 3 5 11 8 8 12 2 13 13 1 3 14 3 14
Ploting Grafik
Salah satu library ploting grafik yang canggih dan banyak digunakan saat ini yaitu ggplot2 yang sudah kalian install secara otomatis diatas tadi, nah jenis grafik yang digunakan yaitu scatter
ggplot(sebaran, aes(x=suhu, y=berat)) + geom_point(size=5, shape=1)
Kalau dilihat sekilas sih ada 3 cluster

Scale data
Hal yang harus dilakukan untuk analisis clustering yaitu diharuskan untuk scale data yang bertujuan untuk mengconvert ke Z Score / Distribusi normal. Adapun persamaan umum untuk scale yaitu
![\[\hat z = \frac{x-\bar x}{\sigma}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-a7f91e13678168debd36fb8a66d445c5_l3.png "Rendered by QuickLaTeX.com")
Ref: https://en.wikipedia.org/wiki/Standard_score
Contoh nya
x<-c(1,5,6,10) z<-(x-mean(x))/sd(x) print(data.frame(x,z))
hasilnya
x z 1 1 -1.2172540 2 5 -0.1352504 3 6 0.1352504 4 10 1.2172540
Bila kalian jumlah kan sum(z) akan menghasilkan NOL. Nah nggak pakai ribet menggunakan kode diatas, kalian hanya cukup panggil function scale() untuk melakukan hal diatas secara lebih mudah.
y=scale(x) print(data.frame(x,y))
hasil nya x akan di z socre menjadi y
x y 1 1 -1.2172540 2 5 -0.1352504 3 6 0.1352504 4 10 1.2172540
Kembali pada kasus sebelumnya yaitu mengubah variabel sebaran menjadi distribusi normal/z dengan perintah berikut
sebaran_scale <- scale(sebaran) #standarisasi data print(sebaran_scale)
hasil
suhu berat
[1,] 0.83074950 -0.08396181
[2,] -0.29478208 1.09150354
[3,] 1.20592670 -0.31905488
[4,] 1.20592670 0.15113126
[5,] -0.66995928 0.85641047
[6,] -0.66995928 -1.72961331
[7,] 0.08039511 -1.25942716
[8,] -0.66995928 1.09150354
[9,] 1.58110389 -0.08396181
[10,] -0.66995928 -0.78924102
[11,] 1.20592670 -0.08396181
[12,] -1.04513647 1.09150354
[13,] -1.42031367 -1.25942716
[14,] -0.66995928 1.32659661
attr(,"scaled:center")
suhu berat
4.785714 8.357143
attr(,"scaled:scale")
suhu berat
2.665407 4.253635
Menentukan jumlah cluster
Untuk menentukan jumlah cluster yang paling optimal dapat kita lakukan dengan beberapa metode yaitu
- Metode Elbow
- Metode Silhoette
- Gap Statistic
Metode Elbow
Gunakan perintah berikut untuk menentukan jumlah cluster yang optimal
fviz_nbclust(sebaran_scale, kmeans, method = "wss") # metode elbow

Kalian bisa melihat ketikan jumlah cluster no 3 secara tiba-tiba grafik langsung turun menuju 4 (patah tajam) sehingga dapat disimpulkan bahwa jumlah cluster optimal k = 3
Metode Silhoette
Gunakan perintah berikut untuk menentukan jumlah cluster yang optimal
fviz_nbclust(sebaran_scale, kmeans, method = "silhouette") # metode silhouette

Untuk menentukan jumlah yang optimal dengan melihat average silhouette width yaitu k =2
Gap Statistic
Gunakan perintah berikut untuk menentukan jumlah cluster yang optimal

Untuk menentukan jumlah yang optimal dengan melihat gaph statistic yaitu k = 3. Dari semuanya hal tersebut diatas maka dilakukan voting saja didapatkan untuk jumlah cluster yang optimal yaitu k=3
Penerapan KMeans Clustering
Perintah yang digunakan pada package cluster yaitu
kmeans(x, centers, iter.max = 10, nstart = 1)
- x: data input berbentuk array, vector, ataupun data frame
- centers: jumla cluster yang akan digunakan
- max: maksimal iterasi secara default bernilai 10
- nstart: nilai bilangan seed random yang digunakan
Kita coba saja dengan perintah berikut
final <- kmeans(sebaran_scale, centers= 3, nstart = 25) print(final)
hasil
K-means clustering with 3 clusters of sizes 5, 4, 5
Cluster means:
suhu berat
1 1.2059267 -0.08396181
2 -0.6699593 -1.25942716
3 -0.6699593 1.09150354
Clustering vector:
[1] 1 3 1 1 3 2 2 3 1 2 1 3 2 3
Within cluster sum of squares by cluster:
[1] 0.3920534 1.5682134 0.3920534
(between_SS / total_SS = 91.0 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss"
[7] "size" "iter" "ifault"
Cara membacanya yaitu
- Centroid suhu dan berat dibagi 3 cluster dengan masing-masing nilai yaitu
- 2059267 -0.08396181
- -0.6699593 -1.25942716
- -0.6699593 1.09150354
- Clustering vector yaitu data no 1 dikategorikan masuk kelas 2, no 3 dikategorikan masuk kelas 3 dan seterusnya
Mendapatkan attribute
Untuk mendapatkan attribute hasil keluaran dari kmeans, kita perlu cek dengan perintah berikut
attributes(final)
hasil
$names [1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" [7] "size" "iter" "ifault" $class [1] "kmeans"
Misalkan kita ingin akses hasil penentuan kelas, maka perintah yang digunakan yaitu
kelas <-final$cluster print(data.frame(sebaran,kelas))
hasil
suhu berat kelas 1 7 8 1 2 4 13 3 3 8 7 1 4 8 9 1 5 3 12 3 6 3 1 2 7 5 3 2 8 3 13 3 9 9 8 1 10 3 5 2 11 8 8 1 12 2 13 3 13 1 3 2 14 3 14 3
Visualisasi Clustering
Untuk menampilkan visualisasi clustering gunakan perintah berikut
fviz_cluster(final, sebaran_scale)
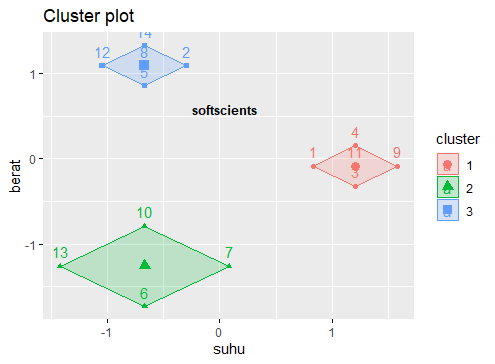
Terlihat sekali antar centroid dan boundary nya