
Sinopsis
Contents
Penggunaan teknik clustering sangat luas sekali mulai dari bidang bisnis ataupun bidang astronomi, misalkan saja untuk bidang bisnis dapat digunakan untuk mengetahui sebuah perilaku konsumen sehingga Perusahaan sedari awal bisa mempersiapkan strategi yang tepat melalui produk yang diinginkan oleh konsumen. Teknik clustering ada banyak sekali seperti KMean Clustering, Fuzzy C-Means Clustering, DBScan (Density-based spatial clustering of applications with noise). Adapun untuk untuk menentukan jumlah cluster terbaik/optimal pada sebuah dataset yang besar perlu dilakukan untuk menghindari trial and error. Penulis sebenarnya telah membahas cara menggunakan 3 metode menggunakan R languange yaitu
- Metode Elbow
- Metode Silhouette
- Gap Statistic
Ref: https://softscients.com/2020/05/01/buku-belajar-dasar-statistika-dengan-r-analisis-cluster/
Namun pada postingan ini, kita akan menggunakan Matlab sebagai jawaban atas pertanyaan email yang masuk dari temen-temen. Yuk kita bahas satu metode saja dulu yaitu Metode Silhouette
Dataset
Dataset yang digunakan terdiri dari 2 atribut yaitu suhu dan berat dengan isinya sebagai berikut
clc;clear all;close all;
data = readtable('data.csv')
X = [data.suhu,data.berat];
hasil
data =
14×3 table
no suhu berat
__ ____ _____
1 7 8
2 4 13
3 8 7
4 8 9
5 3 12
6 3 1
7 5 3
8 3 13
9 9 8
10 3 5
11 8 8
12 2 13
13 1 3
14 3 14
Metode KMeans Clustering
Postingan ini hanya sebagai contoh saja yaitu menggunakan KMeans Clustering karena mudah algoritmanya. Pada pembahasan sebelumnya yang menggunakan R Language diketahui jumlah cluster optimal yaitu 3, maka langsung saja kita set jumlah cluster = 3, jangan lupa set bilangan random agar konsisten
https://softscients.com/2020/03/29/buku-belajar-pemrogaman-matlab-seed-random-generator/
kode lengkapnya untuk menggunakan KMeans yaitu
clc;clear all;close all;
data = readtable('data.csv');
X = [data.suhu,data.berat];
jumlah_cluster = 3;
rand('seed',10);
opts = statset('Display','final');
[label,centroid] = kmeans(X,jumlah_cluster,'Options',opts);
figure;
gscatter(X(:,1),X(:,2),label,'rbg','xod'), title('Clustering Suhu dan Berat')

Seumpuma kita diberikan sebuah pertanyaan, berapa sih jumlah cluster yang optimal? Agar penentuannya tidak manual seperti diatas. Nah untuk menjawab pertanyaan diatas mari kita bahas salah satu teknik cluster evaluation yaitu Silhoette
Cluster evaluation menggunakan Silhouette
Metode Silhoette ini menggabungkan dari dua metode yaitu metode cohesion yang berfungsi untuk mengukur seberapa dekat relasi antara objek dalam sebuah cluster, dan metode separation yang berfungsi untuk mengukur seberapa jauh sebuah cluster terpisah dengan cluster lain. Rumus matematika nya yaitu
![\[Si=\frac{bi-ai}{max(ai,bi)}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-2fb53f5bb9ccda0b58d2d7fea7d0eeb5_l3.png "Rendered by QuickLaTeX.com")
dengan keterangan sebagai berikut
 rata-rata jarak objek dengan semua objek lain yang berada di dalam satu cluster
rata-rata jarak objek dengan semua objek lain yang berada di dalam satu cluster rata-rata jarak objek dengan semua objek lain yang berada pada cluster lain
rata-rata jarak objek dengan semua objek lain yang berada pada cluster lain
Untuk menghitung jarak, bisa menggunakan city block, manhatan distance, ataupun eucleid distance. Nilai hasil silhouette coefficient terletak pada kisaran nilai -1 hingga 1. Semakin nilai silhouette coefficient mendekati nilai 1, maka semakin baik pengelompokan data dalam satu cluster. Sebaliknya jika silhouette coefficient mendekati nilai -1, maka semakin buruk pengelompokan data didalam satu cluster.
Function silhouette untuk mendapatkan nilai coefficient
Kalian tidak usah pusing untuk menerapkan algoritma diatas, kita panggil saja function berikut yang akan langsung menyajikan data dalam bentuk grafik.
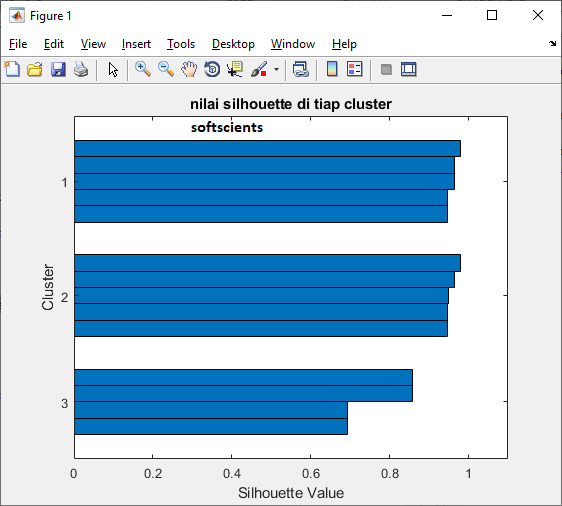
Cara bacanya yaitu ada 3 cluster dan setiap cluster mempunyai nilai silhouette diatas 0.69, kode lengkapnya sebagai berikut
figure
[S,H] = silhouette(X, label);
title('nilai silhouette di tiap cluster')
info = array2table([S,label],'variablenames',{'nilai','label'});
disp(info)
hasil
nilai label _______ _____ 0.94617 2 0.94617 1 0.95 2 0.94617 2 0.94617 1 0.8574 3 0.69349 3 0.98031 1 0.96359 2 0.69349 3 0.98031 2 0.96359 1 0.8574 3 0.96359 1
Kita coba yuk, kalau jumlah cluster = 4, seperti berikut hasilnya
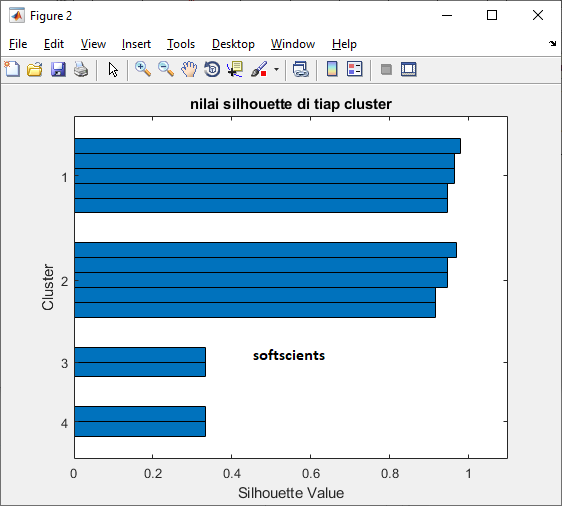
Terdapat nilai yang rendah yaitu pada cluster 3 dan 4. Untuk mendapatkan nilai Score maka cukup gunakan nilai reratanya saja.
score = mean(S)
Evaluasi Cluster
Namun tidak seharusnya sih kalian melakukan hal diatas satu-persatu, mencoba mulai dari jumlah cluster = 3 sampai seterusnya, Kalian cukup menggunakan teknik evaluasi cluster dengan cara menentukan jumlah cluster minimal sampai maksimalnya. Misalkan kita akan menentukan minimal cluster 1 sampai dengan maksimal 6 cluster. Berikut hasil plot nya

Kalian bisa melihat ketika jumlah cluster ==3 merupakan peak nya, sehingga diputuskan jumlah cluster optimalnya yaitu 3. Berikut kode lengkapnya
jumlah_maximal_cluster = 6;
eva = evalclusters(X,'kmeans','silhouette','Distance','sqeuclidean','klist',1:jumlah_maximal_cluster);
figure
plot(eva),title('Nilai Silhouette disetiap jumlah cluster')
disp(eva)
hasil
SilhouetteEvaluation with properties:
NumObservations: 14
InspectedK: [1 2 3 4 5 6]
CriterionValues: [NaN 0.6821 0.9063 0.7798 0.8213 0.5741]
OptimalK: 3