
Pengelompokan Data K-means adalah algoritma yang kuat untuk pencarian kemiripan. Ada banyak library yang cukup cepat dalam menerapkan K-Means Clustering salah satunya yaitu faiss Facebook AI Research menjadi juara yang terbaik. Melalui beberapa baris kode yang dibagikan dalam demonstrasi ini, faiss mengungguli implementasinya dalam kecepatan dan akurasi scikit-learn. #matlab
K-Means adalah algoritma iteratif, yang mengelompokkan titik data menjadi k cluster, masing-masing diwakili dengan mean / titik pusat (centroid). Pelatihan dimulai dengan beberapa tebakan awal dan kemudian berganti-ganti antara dua langkah: tugas dan pembaruan/update.
Dalam fase penugasan, kita menetapkan setiap titik ke cluster terdekat (menggunakan jarak Euclidean antara titik dan sentroid). Pada langkah pembaruan, kita menghitung ulang setiap sentroid dengan menghitung titik rata-rata dari semua titik yang ditetapkan ke kluster tersebut pada langkah saat ini.
Kualitas akhir pengelompokan dihitung sebagai jumlah jarak dalam klaster, di mana untuk setiap kluster, kita menghitung jumlah jarak Euclidean antara titik-titik dalam kluster tersebut dan pusatnya. Ini juga disebut inersia.
Untuk prediksi, kita melakukan pencarian tetangga 1-terdekat (kNN dengan k = 1) antara titik baru dan centroid.
Library Scikit-Learn vs Faiss
Di kedua pustaka, kita harus menentukan hyperparameter algoritme: jumlah cluster, jumlah initialnya (masing-masing dimulai dengan tebakan awal lainnya), dan jumlah iterasi maksimal. Seperti yang dapat kita lihat dari contoh, inti dari algoritma ini adalah untuk mencari tetangga terdekat, khususnya centroid terdekat, baik untuk pelatihan maupun prediksi. Dan di situlah faiss lipat lebih cepat daripada Scikit-learn! Ini memanfaatkan implementasi C ++ yang hebat, konkurensi jika memungkinkan, dan bahkan GPU, jika kita mau.
Mengimplementasikan clustering K-Means dengan faiss
Sebuah fitur hebat dari faiss adalah ia memiliki instruksi instalasi dan build serta dokumentasi yang sangat baik dengan contoh-contoh. Setelah instalasi, kita dapat menulis clustering yang sebenarnya. Kodenya cukup sederhana karena kita hanya meniru Scikit-learn API. Agar lebih mudah, kita buat saja sebuah class dan method yang meniru scikit-Learn API yaitu ada nya method fit() dan predict(). Berikut kode yang akan kita gunakan.
import faiss
import numpy as np
class FaissKMeans:
def __init__(self, n_clusters=8, n_init=10, max_iter=300):
self.n_clusters = n_clusters
self.n_init = n_init
self.max_iter = max_iter
self.kmeans = None
self.cluster_centers_ = None
self.inertia_ = None
def fit(self, X, y):
self.kmeans = faiss.Kmeans(d=X.shape[1],
k=self.n_clusters,
niter=self.max_iter,
nredo=self.n_init)
self.kmeans.train(X.astype(np.float32))
self.cluster_centers_ = self.kmeans.centroids
self.inertia_ = self.kmeans.obj[-1]
def predict(self, X):
return self.kmeans.index.search(X.astype(np.float32), 1)[1]
Beberapa hal yang perlu kita perhatikan yaitu
- faiss memiliki kelas Kmeans built-in khusus untuk tugas ini, tetapi argumennya memiliki nama yang berbeda dengan di Scikit-learn (lihat dokumen)
- kita harus memastikan bahwa kita menggunakan tipe np.float32, karena faiss hanya bekerja dengan tipe ini
- kmeans.obj mengembalikan daftar kesalahan melalui pelatihan, jadi untuk mendapatkan hanya yang terakhir, seperti di Scikit-learn, kita menggunakan indeks [-1]
- prediksi dilakukan dengan struktur data Indeks, yang merupakan blok bangunan dasar faiss, dan digunakan di semua penelusuran tetangga terdekat
- dalam prediksi, kita melakukan pencarian kNN dengan k = 1, mengembalikan indeks dari sentroid terdekat dari self.cluster_centers_ (indeks [1], karena index.search () mengembalikan jarak dan indeks)
Perbandingan waktu dan akurasi
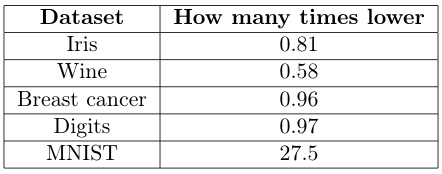
Saya telah memilih beberapa set data populer yang tersedia di Scikit-learn untuk perbandingan. Pelatihan dan waktu prediksi dibandingkan. Untuk membaca lebih mudah, saya telah secara eksplisit menulis berapa kali lebih cepat pengelompokan berbasis faiss daripada Scikit-learn. Untuk perbandingan kesalahan, saya baru saja menulis berapa kali lebih rendah kesalahan yang dicapai pengelompokan berbasis faiss (karena jumlahnya besar dan tidak terlalu informatif).
Semua waktu ini telah diukur dengan fungsi time.process_time () yang mengukur waktu proses, untuk hasil yang lebih akurat. Hasilnya adalah rata-rata 100 running, kecuali untuk MNIST, yang membutuhkan waktu terlalu lama untuk Scikit-learn, dan saya harus melakukan 5 running.
Untuk contoh MNIST, kalian bisa menggunakan teknik PCA bisa mereduksi menjadi 3 komponen utamanya


Seperti yang bisa kita lihat, untuk clustering K-Means untuk dataset kecil (4 dataset pertama) versi berbasis faiss lebih lambat untuk pelatihan dan memiliki error yang lebih besar. Untuk prediksi, ini bekerja lebih cepat secara universal.
Untuk kumpulan data MNIST yang lebih besar, faiss adalah pemenang yang jelas. Latihan 20,5 kali lebih cepat sangat besar, terutama karena mengurangi waktu dari hampir 3 menit menjadi kurang dari 8 detik! Prediksi 1,5 kali lebih cepat juga bagus. Pencapaian sebenarnya, bagaimanapun, adalah kesalahan spektakuler 27,5 kali lebih rendah. Ini berarti bahwa untuk kumpulan data dunia nyata yang lebih besar, versi berbasis faiss jauh lebih akurat. Dan ini hanya membutuhkan 25 baris kode!
Jadi berdasarkan ini: jika kalian memiliki kumpulan data yang besar (setidaknya beberapa ribu sampel), versi berbasis faiss jelas lebih baik. Untuk kumpulan data mainan kecil, Scikit-learn adalah pilihan yang lebih baik; namun, jika Anda memiliki GPU, versi faiss yang dipercepat GPU dapat menjadi lebih cepat.
Dengan 25 baris kode, kita bisa mendapatkan peningkatan kecepatan dan akurasi yang sangat besar untuk pengelompokan K-Means untuk kumpulan data berukuran wajar dengan pustaka faiss.