

Python dan R adalah bahasa pemrograman yang mendominasi dalam ekosistem data science. Keduanya menyediakan banyak paket dan kerangka kerja untuk melakukan analisis dan manipulasi data yang efisien. Pada artikel ini, kami akan membandingkan dua perpustakaan yang sangat populer dalam hal manipulasi data dan tugas transformasi / berbasis data frame tabel.
- Pandas: Analisis data dan pustaka manipulasi untuk Python
- Dplyr: Paket manipulasi data untuk R
Contoh berikut terdiri dari beberapa tugas sederhana yang diselesaikan oleh panda dan dplyr. Ada banyak pilihan untuk menggunakan paket ini. Saya menggunakan R-studio IDE untuk R dan Spyder untuk Python.
Langkah pertama adalah menginstal dependensi dan membaca data (misalkan saya punya data disimpan di D:/DirectMarketing.csv). Bila kalian menggunakan anaconda maka package pandas sudah tersedia dalam installer tersebut.
#Python
import numpy as np
import pandas as pd
marketing = pd.read_csv("D:/DirectMarketing.csv")
Sedangkan untuk R, kalian bisa install melalui cara berikut
#R
> library(readr)
> library(dplyr)
> marketing <- read_csv("D:/DirectMarketing.csv")
Mengenai data DirectMarketing.csv, data tersebut berisi nama-nama customer sebagai berikut
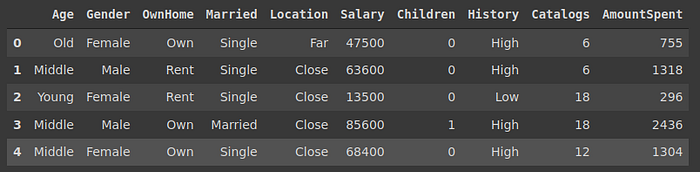
Ditampilkan dalam RStudio

Mari kita coba beberapa tugas untuk Pandas dan Dplyr seperti
Filter berdasarkan suatu kondisi
Contents
Tugas: Memfilter baris yang jumlah pengeluarannya lebih dari 2000. Kode berikut membuat dataframe baru atau berbasis tibble sesuai dengan kondisi yang diberikan.
untuk versi Python / Pandas
#pandas high_amount = marketing[marketing.AmountSpent > 2000]
untuk versi R / dplyr
#dplyr high_amount <- filter(marketing, AmountSpent > 2000)
Untuk panda, kami menerapkan kondisi pemfilteran pada pandas dataframe seperti yang menggunakan indeks yang dikondisikan dengan operator perbandingan, sedangkan untuk dplyr, menggunakan fungsi filter.
Filter pada berbagai kondisi
Tugas: Memfilter baris yang jumlah pengeluarannya lebih dari 2000 dan riwayatnya tinggi.
untuk versi Python / Pandas
#pandas new = marketing[(marketing.AmountSpent > 2000) & (marketing.History == 'High')]
untuk versi R / dplyr
#dplyr new <- filter(marketing, AmountSpent > 2000 & History == 'High')
Untuk kedua pustaka, kita dapat menggabungkan beberapa kondisi menggunakan operator logika.
Membuat Dataframe
Kami akan membuat contoh dataframe / python dan tibble/R dengan kode sebagai berikut
Versi Pandas – Python
#pandas
df = pd.DataFrame({
'cola':[1,3,2,4,6],
'colb':[12, 9, 16, 7, 5],
'colc':['a','b','a','a','b']
})
Versi Dplyr – R
#dplyr
df <- tibble(cola = c(1,3,2,4,6),
colb = c(12, 9, 16, 7, 5),
colc = c('a','b','a','a','b')
)
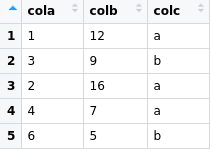
Sortir berdasarkan kolom
Tugas: Mengurutkan baris dalam df berdasarkan nama colom cola.
Versi Pandas – Python
#pandas
df.sort_values('cola')
Versi Dplyr – R
#dplyr arrange(df, cola)
Kkita menggunakan fungsi sort_values di pandas dan fungsi mengatur di dplyr. Keduanya mengurutkan nilai dalam urutan menaik-ascending secara default
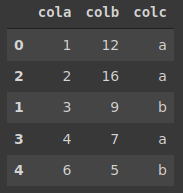
Urutkan berdasarkan beberapa kolom
Tugas: Mengurutkan baris berdasarkan colc dalam urutan pertama dan cola dalam urutan naik yaitu colom colc dan cola
Ini lebih rumit dari contoh sebelumnya tetapi logikanya sama. Kita juga perlu mengubah perilaku default pengurutan dalam urutan menaik-ascending.
Versi Pandas – Python
#pandas df.sort_values(['colc','cola'], ascending=[False, True])
Versi Dplyr – R
#dplyr arrange(df, desc(colc), cola)

Untuk pandas, nilainya diurutkan berdasarkan kolom dalam daftar yang diberikan. Urutan kolom dalam daftar penting. Kita juga meneruskan daftar ke parameter menaik -ascending, jika kita ingin mengubah perilaku default.
Untuk dplyr, sintaksnya sedikit lebih sederhana. Kita dapat mengubah perilaku default dengan menggunakan kata kunci desc.
Memilih subset kolom
Kita mungkin hanya membutuhkan beberapa kolom dalam kumpulan data. Baik pandas dan dplyr menyediakan cara sederhana untuk memilih kolom atau daftar kolom.
Tugas: Membuat subset dari dataset dengan memilih kolom location, salary, amount dan spent
Versi Pandas – Python
#pandas subset = marketing[['Location','Salary','AmountSpent']]
Versi Dplyr – R
#dplyr subset = select(marketing, Location, Salary, AmountSpent)
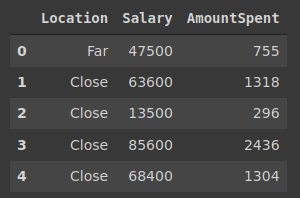
Membuat kolom baru berdasarkan yang sudah ada
Dalam beberapa kasus, kita perlu menggabungkan kolom dengan transformasi untuk membuat kolom baru.
Tugas: Buat kolom baru yang disebut dengan spent_ratio yang merupakan rasio jumlah yang dibelanjakan terhadap gaji.
Versi Pandas – Python
#pandas subset['spent_ratio'] = subset['AmountSpent'] / subset['Salary']
Versi Dplyr – R
#dplyr mutate(subset, spent_ratio = AmountSpent / Salary)
Kita menggunakan fungsi mutate dplyr sedangkan pandas dapat langsung menerapkan operasi matematika sederhana.

Kesimpulan
Kita telah membandingkan bagaimana tugas manipulasi data sederhana dilakukan dengan pandas dan dplyr. Ini hanyalah operasi dasar tetapi penting untuk memahami operasi yang lebih kompleks dan canggih.
Ada lebih banyak fungsi dan metode yang disediakan perpustakaan ini. Faktanya, keduanya adalah alat analisis data yang cukup serbaguna dan kuat.