
Normal Distribution adalah salah satu hal paling mendasar di alam semesta kita. Itu muncul hampir di mana-mana, di alam, sains, matematika. Bahkan fenomena paling gila seperti proton yang saling bertabrakan, aksi kerumunan orang, dll. Dapat dimodelkan menggunakan distribusi normal. Rumus umum mengenai teori normal distribution yaitu
![\[f(x) = \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}(\frac{x-m}{\sigma})^2}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-5177e3fab25727aad9ee359fa48c65db_l3.png "Rendered by QuickLaTeX.com")
dengan  bilangan natural dan
bilangan natural dan  adalah standar deviasi dan
adalah standar deviasi dan  adalah nilai rata-ratanya
adalah nilai rata-ratanya
Ketika kita memplot data yang terdistribusi normal, biasanya pola berbentuk lonceng:
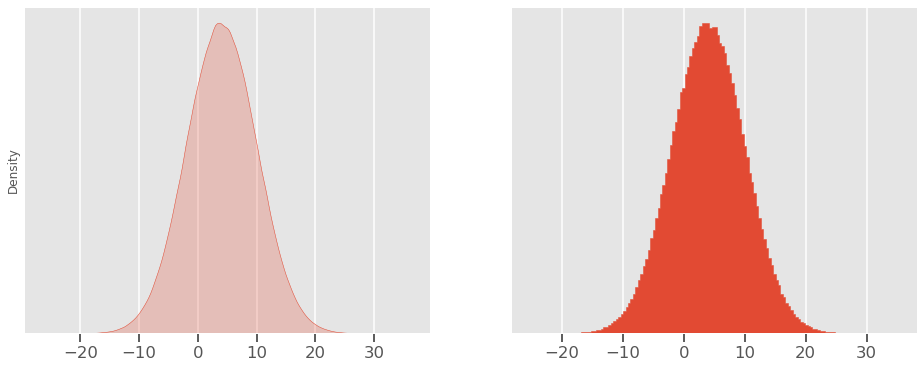
Itulah mengapa kita juga akan mendengarnya disebut kurva lonceng atau distribusi Gaussian (dinamai menurut ahli matematika Jerman, Karl Gauss yang menemukannya).
Ini memiliki banyak implikasi dalam dunia bisnis juga. Ada di mana-mana sehingga data scientist dan ahli statistik menganalisis banyak data baru yang dimulai dengan asumsi normalitas. Selain itu, karena teorema batas pusat yang akan kita bahas nanti, Anda dapat memperoleh distribusi normal meskipun distribusi yang mendasarinya tidak normal.
Dalam posting ini, kita akan belajar bagaimana menggunakan julukan raja distribusi ini dalam alur kerja sehari-hari dengan membangun pemahaman teoritis dan menerapkan ide tersebut dalam sebuah kode apik
Contents
Distribusi normal adalah hal terbaik yang dapat mungkin kita impikan selama analisis yang berkenaan dengan data. Mengapa saya sebut demikian! Karena data tersebut memiliki banyak properti ‘bagus’ yang membuatnya mudah untuk dikerjakan dan mendapatkan hasil.
Sebelum kita melihat kurva Normal Distribution berbentuk lonceng. Ketinggian kurva ditentukan oleh nilai deviasi standar. Deviasi standar yang lebih kecil berarti lebih banyak titik data yang dikelompokkan di sekitar mean sementara nilai yang lebih besar mewakili distribusi yang lebih tersebar. Ini juga dapat diartikan bahwa kerapatan (lebih lanjut tentang ini nanti) dari kurva ditentukan oleh deviasi standar.
Rerata Normal Distribution bergerak pusat di sekitar XAxis
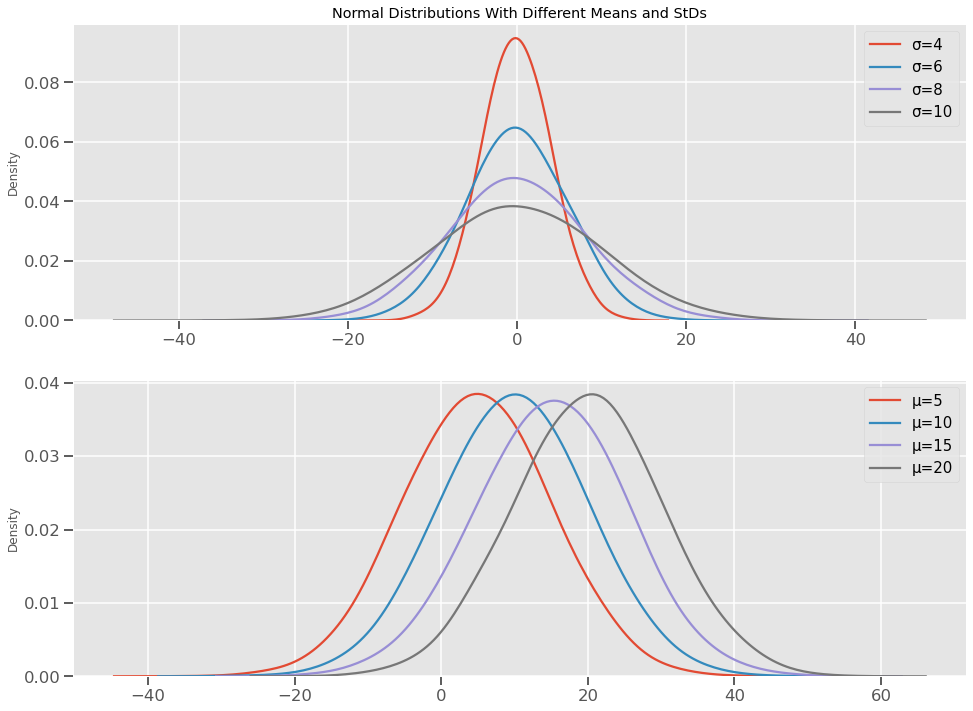
Seperti yang kalia lihat, Normal Distribution yang secara teoritis sempurna memiliki satu puncak dan juga di mana garis simetri melintasi distribusi. Selain itu, pernyataan berikut dapat dibuat tentang Normal Distribution yang sempurna:
- Mean, median, dan mode semuanya sama
- Tepatnya separuh nilai berada di kiri garis simetri dan tepat separuh di kanan
-
Luas total di bawah kurva selalu sama dengan 1
Tentu saja, jarang sekali data asli mengikuti pola berbentuk lonceng yang sempurna.
Namun, ada baiknya memperkirakan kemiripan antara Normal Distribution sempurna dan distribusi yang mendasarinya untuk melihat apakah kita dapat memperlakukannya dengan cukup baik seperti normalnya. Kita akan melihat bagaimana menghasilkan proses kesamaan ini di beberapa bagian berikutnya.
Apa itu Probability Density Function sebenarnya
Sejauh ini, kita melihat dan melihat plot Normal Distribution tetapi kita tidak menanyakan fungsi apa yang menghasilkan plot ini. Untuk menjawab ini, kita perlu memahami apa itu distribusi probabilitas kontinu – Probability Density Function – PDF.
Menurut statistik deskriptif, ada dua jenis data: diskrit dan kontinu. Setiap data yang dicatat dengan penghitungan adalah diskrit (nilai bilangan bulat) seperti hasil nilai tes, jumlah apel yang kita makan per hari, berapa kali kita berhenti di lampu merah, dll. Sebaliknya, data berkelanjutan adalah data apa pun yang direkam dengan mengukur seperti tinggi, berat, jarak, dll. Waktu itu sendiri juga dianggap sebagai data kontinu.
Salah satu aspek yang menentukan dari data kontinu adalah bahwa data yang sama dapat direpresentasikan dalam unit pengukuran yang berbeda. Misalnya jarak dapat diukur dalam mil, kilometer, meter, sentimeter, milimeter dan daftarnya terus berlanjut. Tidak peduli seberapa kecil, unit pengukuran yang lebih kecil dapat ditemukan untuk data kontinu. Ini juga menunjukkan bahwa ada banyak titik desimal yang tak terhingga untuk satu pengukuran.
Kemungkinan, jika eksperimen acak menghasilkan hasil yang kontinu, ini akan memiliki distribusi probabilitas yang kontinu. Misalnya, variabel acak X menyimpan jumlah hujan setiap hari dalam inci. Sekarang, sangat tidak mungkin jumlah hujan mengambil nilai bilangan bulat karena kita tidak dapat mengatakan bahwa hujan turun tepat 2 inci hari ini, tidak ada satu pun molekul air yang lebih atau kurang. Probabilitas terjadinya hal itu sangat kecil sehingga kita dapat dengan aman mengatakannya adalah 0.
Hal yang sama juga berlaku untuk nilai lain seperti 2.1 atau 2.0000091 atau 2.000000001. Peluang terjadinya hujan tepat pada suatu jumlah selalu 0. Itulah mengapa untuk distribusi kontinu memiliki fungsi berbeda yang disebut Fungsi Densitas Probabilitas – Probability Density Function – PDF.
Fungsi Massa Probabilitas – Probability Mass Functions – PMS yang dituangkan dalam probabilitas hasil sebagai height – tinggi.
from empiricaldist import Pmf # pip install empiricaldist outcomes = [1, 2, 3, 4, 5, 6] pmf_die = Pmf.from_seq(outcomes) pmf_die
hasil

Diplotlkan dalam bar plot
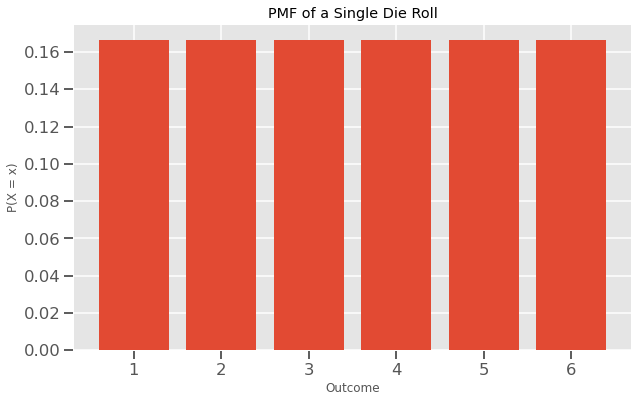
Seperti yang kalian lihat, tinggi setiap batang mewakili probabilitas hasil tunggal seperti 1, 3, atau 5. Semuanya berada pada ketinggian yang sama karena plot bar memiliki distribusi seragam – uniform distribution yang terpisah.
Ingat rumus paling favorit ahli statistik?
![\[f(x) = \frac{1}{\sigma \sqrt{2 \pi}} e^{\frac{1}{2}\frac{x-m}{\sigma}}\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-e49044c6899b64cf1ca778e77f517cc0_l3.png "Rendered by QuickLaTeX.com")
Itu adalah rumus untuk Fungsi Kepadatan Probabilitas Probability Density Function – PDF dari normal distribution. Dengan sendirinya, ia tidak bisa berbuat banyak. Untuk Normal Distribution dengan mean dan deviasi standar yang diketahui, Kita dapat memasukkan nilai x apa pun ke dalam fungsi tersebut. Ini menghasilkan tinggi kurva pada titik itu di XAxis. Perhatikan bahwa saya tidak mengatakan probabilitas, hanya ketinggian kurva. Seperti yang saya katakan, untuk area distribusi kontinu mewakili probabilitas tertentu. Nah, garis tipis pada plot tidak memiliki luas jadi kita perlu menyusun ulang pertanyaan awal kita.
Untuk eksperimen acak, misaklan saya telah mengamati jumlah hujan setiap hari, tentu bila ada pertanyaan seperti berapa probabilitas hujan 3 inci atau 2.5 inci karena jawabannya akan selalu 0. Sebagai gantinya, sekarang kami bertanya berapa probabilitas hujan antara 1.6 dan 1.9 inci. Ini sama dengan menanyakan luas area di bawah kurva antara dua garis ini:
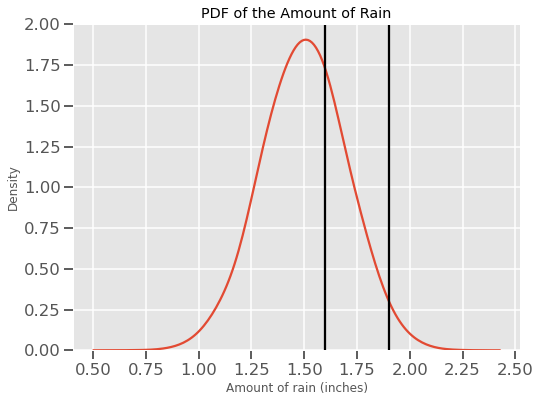
Perhitungan kalkulus untuk rumus normal distribution adalah
![\[\int_{1.6}^{1.9} \frac{1}{\sigma \sqrt{2 \pi}} e^{\frac{1}{2}\frac{x-m}{\sigma}} dx\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-b4a285a421dd9f5a0cc8b69ed3c0a4f0_l3.png "Rendered by QuickLaTeX.com")
Rumus di atas menghasilkan beberapa angka antara 0 dan 1 sebagai kemungkinan hujan turun antara 1,6 dan 1,9 inci. Sekarang, pertanyaan yang jelas adalah apa yang kita interpretasikan dari YAxis karena tidak memberikan probabilitas apapun
Cumulative Distribution Function
Pada titik ini, saya pikir kita sudah sepakat bahwa plot distribusi normal memiliki kurva. Kita sudah pernah melihat yang berbentuk lonceng, sekarang saatnya melihat yang sigmoid:
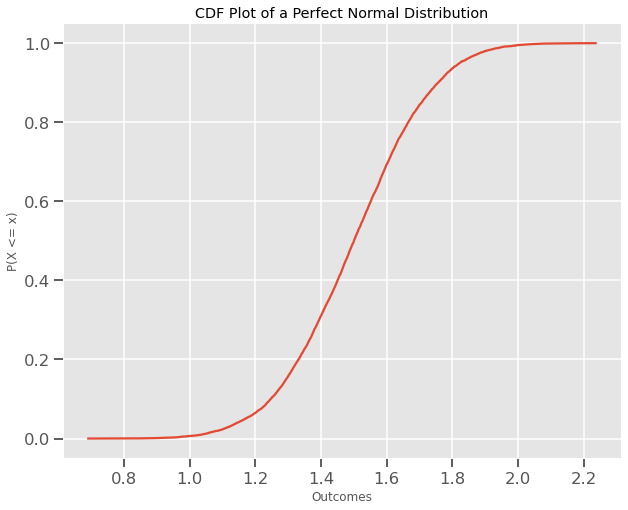
Sebelum kita menafsirkan ini, mari kita pahami apa itu Fungsi Distribusi Kumulatif – Cumulative Distribution Function (CDF). Sebaiknya kita mulai dengan contoh sederhana
Cdf.from_seq([1, 2, 3, 4, 5, 6])
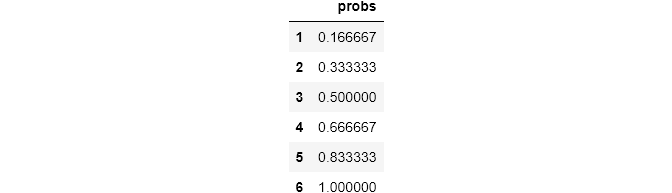
Jika kita mengambil nomor acak dari distribusi apa pun dan memasukkannya ke CDF, hasilnya memberi tahu kita kemungkinan mendapatkan nilai yang kurang dari atau sama dengan nomor acak itu. Misalkan kita memiliki distribusi 1, 2, 3, 4, 5, 6. Misalkan kita memilih 4 secara acak.
Dalam notasi, ini akan terlihat seperti ini
![\[f(x) = p(X \leq x)\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-37ef43c8e2c04e6d54d78a009f30568b_l3.png "Rendered by QuickLaTeX.com")
Jadi, untuk menghitung CDF, langkah awalnya adalah menghitung probabilitas individu dari setiap hasil. Kemudian, Probabilitas Kumulatif dari setiap nilai x akan menjadi jumlah dari semua probabilitas individu terurut hingga x dalam distribusi kita.
Kurva ini juga disebut sigmoid. Rata-rata Normal Distribution adalah pusat kurva:
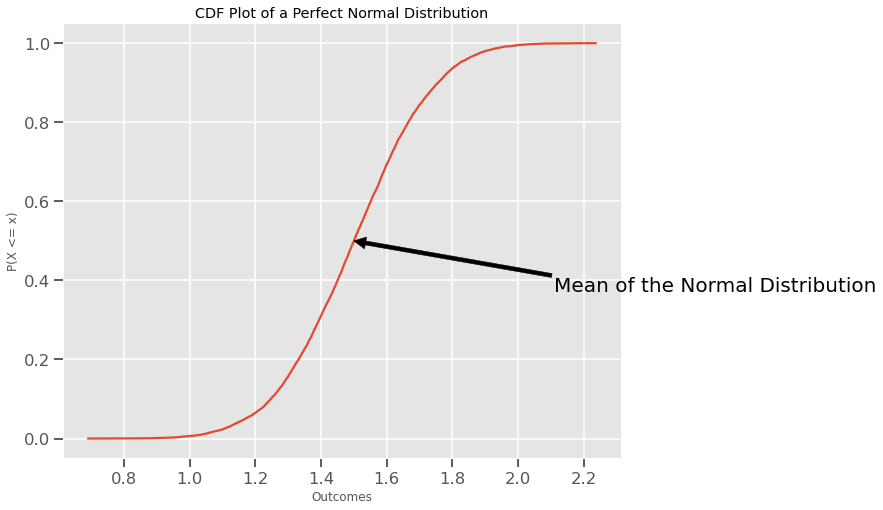
Dengan menggunakan CDF, kalian tidak harus menggunakan rumus Normal Distribution. Misalnya, untuk menemukan probabilitas X yang jatuh diantara 1,6 dan 1,9; kalian hanya akan menemukan CDF batas atas dan mengurangi CDF dari batas bawah:
![\[CDF(1.9) - CDF(1.6) = \int_{1.6}^{1.9} \frac{1}{\sigma \sqrt{2 \pi}} e^{\frac{1}{2}\frac{x-m}{\sigma}} dx\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-f8248892eafc10aeb73148a67ba93cf2_l3.png "Rendered by QuickLaTeX.com")
Pakai cara ini saja
Terakhir, saya akan mengungkapkan bagaimana membuat semua kurva lonceng dan CDF ini. Pertama-tama, kurva lonceng dari distribusi mana pun dapat dibuat menggunakan fungsi kdeplot kepunyaan library dari Seaborn.
Untuk memplot distribusi ini, kita perlu membuat distribusi itu sendiri. Ini bisa dilakukan dengan menggunakan numpy.random.normal
import numpy as np normal_dist = np.random.normal(loc=5, scale=2, size=10000) >>> normal_dist
hasil
array([7.8619458 , 2.65074237, 2.15212128, ..., 4.1277429 , 6.30277494,
8.21359059])
Di sini, saya menggambar sampel 10k dari distribusi normal dengan rata-rata 5 dan deviasi standar 2. Selanjutnya, kita akan menggunakan kdeplot untuk membuat kurva:
from matplotlib import pyplot as plt
import seaborn as sns
# Create fig, ax objects
fig, ax = plt.subplots(figsize=(10, 8))
# Create the curve
sns.kdeplot(normal_dist,ax=ax)
# Labeling
ax.set(title='The PDF plot of Normal Distribution With Mean 5 and StD 2',
xlabel='X values', ylabel='Density')
plt.show();

Atau kalian bisa menggunakan kode berikut
def pdf(x):
mean = np.average(x)
std = np.std(x,ddof=1)
a = 1/(std*(np.sqrt(2*np.pi)))
b = np.e**(-0.5*((x-mean)/std)**2)
return a*b
normal_dist = np.random.normal(loc=5, scale=2, size=10000)
y2 = pdf(normal_dist)
plt.figure()
plt.scatter(normal_dist,y2)
plt.xlabel('wind speed')
plt.ylabel('pdf')
plt.show()

Sekarang, ada sedikit lebih banyak pekerjaan yang diperlukan untuk membuat CDF. Kita bisa membuatnya dengan mudah yaitu menggunakan fungsi Cdf dari pustaka empiricaldist : Kalian install dulu pakai pip pip install empiricaldist
import numpy as np from empiricaldist import Cdf normal_dist = np.random.normal(2, 5, size=1000) normal_cdf = Cdf.from_seq(normal_dist)
hasil
-1.874067 0.1 -1.135722 0.2 1.706556 0.3 1.924427 0.4 2.061186 0.5 2.800270 0.6 4.331832 0.7 4.333651 0.8 6.254559 0.9 7.186077 1.0 dtype: float64
Kita akan plot
from matplotlib import pyplot as plt
# Create fig, ax objects
fig, ax = plt.subplots(figsize=(10, 8))
# Plot the CDF
ax.plot(normal_cdf)
# Labeling
ax.set(title='CDF of a Perfect Normal Distribution',
xlabel='Outcomes', ylabel='P(X <= x)')
plt.show();

Seperti yang diharapkan, kita melihat sigmoid halus di plot – kalian bisa set nilai semula 1000 menjadi 10 ribu.
Praktek penggunaan CDF
Terakhir, kita akan melihat kasus penggunaan praktis. Kita akan menggunakan plot CDF untuk mengetahui apakah distribusi yang diberikan normal. Sebagai contoh, saya akan memuat dataset Iris dari Seaborn:
import seaborn as sns
iris = sns.load_dataset('iris').dropna()
print(iris.head(5))
hasil
sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa
>>> iris.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 150 non-null float64 1 sepal_width 150 non-null float64 2 petal_length 150 non-null float64 3 petal_width 150 non-null float64 4 species 150 non-null object dtypes: float64(4), object(1) memory usage: 7.0+ KB
Pada bagian awal banyak fenomena alam yang mengikuti distribusi normal sehingga dapat diasumsikan bahwa pengukuran jenis bunga iris mengikuti distribusi normal. Mari kita lihat seberapa benar kita:
from matplotlib import pyplot as plt
# Create fig, ax objects
fig, ax = plt.subplots(figsize=(10, 8))
# Create the KDE plot to see if it follows a normal dist
sns.kdeplot(iris['sepal_length'], ax=ax)
# Labeling
ax.set(title='PDF of Sepal Length of Iris Flowers',
xlabel='Length (mm)', ylabel='Density')
plt.show();

Dari perkiraan secara sekilas saja, kita sudah bisa melihat bahwa asumsi kita tidak benar.
Namun, hanya untuk memastikan akan lebih baik jika membuat plot normal distribution yang sempurna untuk perbandingan.
Normal Distribution mana yang kita perlu Tentu saja, ada banyak Normal Distribution, jadi bagaimana kita memilihnya?
Sebaiknya plot Normal Distribution yang memiliki mean dan deviasi standar yang sama dari distribusi yang mendasarinya sehingga kedua distribusi tersebut akan dekat:
import numpy as np
# Create fig, ax objects
fig, ax = plt.subplots(figsize=(10, 8))
# Create the KDE plot to see if it follows a normal dist
sns.kdeplot(iris['sepal_length'], ax=ax, label='Underlying Distribution')
# Get the parameters from the underlying dist
sepal_mean = iris['sepal_length'].mean()
sepal_std = iris['sepal_length'].std()
# Create the ND using the above params
sepal_normal = np.random.normal(sepal_mean, sepal_std, size=10000)
# Add it to the plot for comparison
sns.kdeplot(sepal_normal, label='Perfect Normal Dist')
# Labeling
ax.set(title='PDF of Sepal Length of Iris Flowers',
xlabel='Length (mm)', ylabel='Density')
# Show the legend
ax.legend(fontsize=15)
plt.show()

Sekarang, jauh lebih jelas bahwa kedua distribusi itu sama sekali berbeda. Namun, ada banyak kasus di mana kedua distribusi sangat dekat satu sama lain tetapi tidak persis sama. Membandingkan kurva lonceng yang dekat bukanlah hal yang mudah bagi mata manusia. Jadi kita perlu menggunakan visual yang lebih baik untuk membandingkan distribusi semacam itu. Saya pikir kalian sudah dapat menebaknya tetapi saya akan menggunakan CDF saja.
Saya akan menggunakan teknik yang sama seperti di atas tetapi mengganti PDF dengan CDF:
from empiricaldist import Cdf
# Create fig, ax objects
fig, ax = plt.subplots(figsize=(10, 8))
# Create the CDF of sepal lengths
sepal_cdf = Cdf.from_seq(iris['sepal_length'])
# Plot the CDF
ax.plot(sepal_cdf, label='Underlying Dist', marker='.', linestyle='none')
# Create the perfect Normal Dist and its CDF
normal_dist = np.random.normal(sepal_mean, sepal_std, size=10000)
normal_cdf = Cdf.from_seq(normal_dist)
# Plot it
ax.plot(normal_cdf, label='Perfect Normal CDF')
# Show the legend
ax.legend(fontsize=15)
# Labeling
ax.set(title='Comparison of CDF of the Perceft '
'and the Underlying Distributions',
xlabel='Sepal Length (mm)',
ylabel='P(X <= x)')
plt.show()

Seperti biasa, Saya membuat CDF dengan panjang sepal dan memplotnya sebagai garis. Selanjutnya, saya mengambil mean dan std dari panjang sepal dan menghasilkan distribusi normal yang sempurna dengan parameter ini. Kemudian, kami membuat CDF untuk itu juga dan memplotnya di atas satu sama lain.
Untuk memperjelas, saya menggunakan titik sebagai penanda yang menghilangkan gaya garis. Tampilan ini memberikan perbandingan visual yang jauh lebih baik daripada perbandingan baris demi baris.
Kesimpulan
Saya sudah membahas banyak hal. Namun, masih banyak yang harus dipelajari tentang distribusi normal. Yaitu, saya tidak membahas Teorema Batas Pusat- Central Limit Theorem atau aturan Empiris, atau banyak topik lainnya. Silahkan kalian belajar sendiri, saya sudah meninggalkan tautan ke beberapa sumber yang membantu kita dalam memahami topik tersebut.
ref:
- Normal Distribution by Brilliant.org
- Central Limit Theorem by Brilliant.org
- Normal Distribution by Khan Academy
- The Wikipedia page