
Tuning Model adalah salah satu kerjaan dari data science lho setelah mendapatkan dataset dari data engineer. Tuning model bisa dimulai dari goal yang ingin dicapai dengan cara memilih algoritma yang tepat! ada banyak sekali algoritma yang bisa kita gunakan seperti klasifikasi, clustering, segmentation bisa menggunakan statistik biasa bahkan deep machine learning! Saya ambil contoh pada kasus sebelumnya yaitu klasifikasi fruit berdasarkan mean RGB.
Sebagai pengingat, dataset tersebut telah disiapkan oleh data engineer dengan sangat baik melalui tahapan image processing tentunya. Adapun dataset tersebut yaitu
- ciri fitur yaitu RED, GREEN, dan BLUE sedangkan
- target/kelas yaitu KELAS dengan kategorikal
- Apple Braeburn
- Apple Crimson Snow
- Apple Golden 1
- Apple Golden 2
Ada banyak pilihan tools untuk mendapatkan visualisasi dataset, untuk tools yang ditulis dari bahasa java ada WEKA ataupun python – Orange atau bahkan kalian suka coding menggunakan RStudio. Biar nyambung dengan pembahasan sebelumnya, saya menggunakan WEKA saja.
Visualisasi Ciri Fitur vs Kelas/Target
Contents
WEKA sangat bagus sekali dalam melakukan visualisasi data, berikut tampilan nya, perhatikan pada KELAS vs BLUE tidak mengalami overlaping data
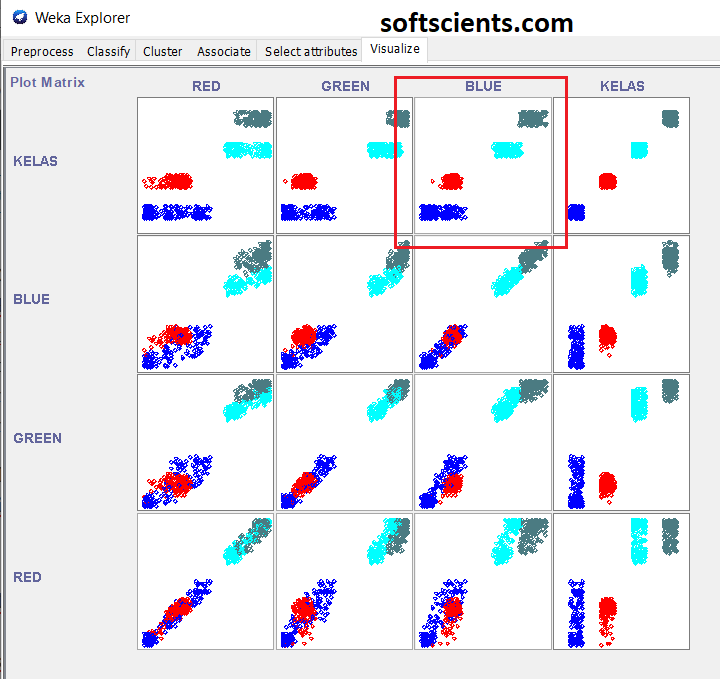
Kita perjelas lagi ada apa didalamnya
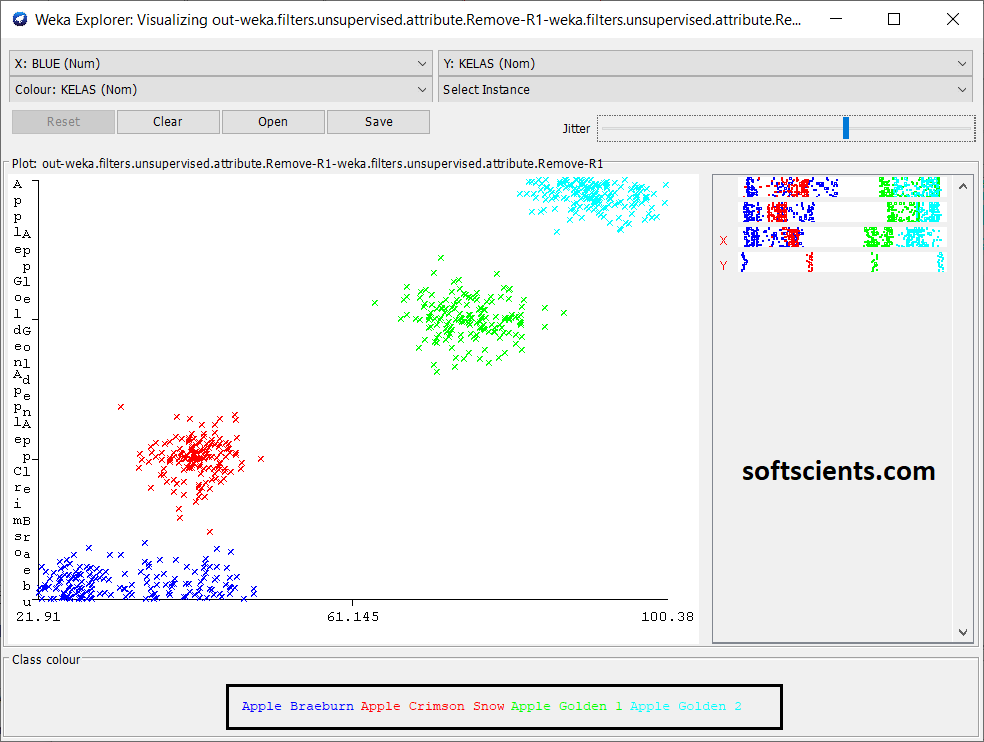
Kita menyimpulkan bahwa BLUE bisa memisahkan dengan baik antara kelas
- Apple Golden 2
- Apple Golden 1,
adapun untuk kelas
- Apple Breaburn dan
- Apple Crimson Snow
tidak bisa karena saling overlapping! kita buktikan dengan BLUE vs BLUE
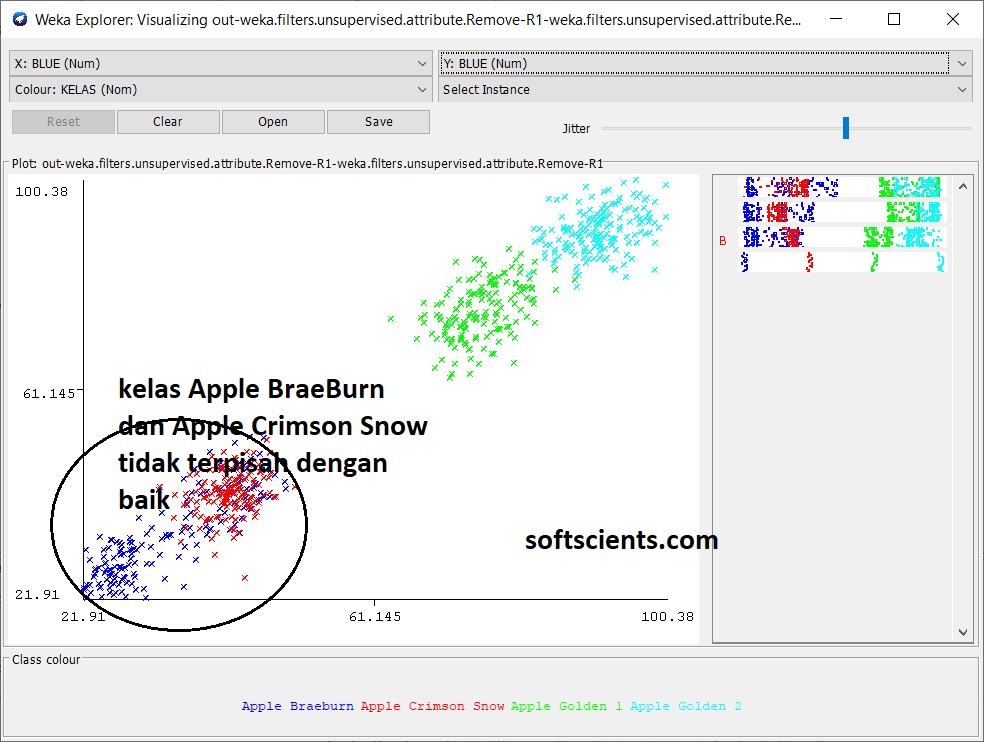
bagaimana dengan RED dan GREEN? kalian bisa melihat sendiri bahwa 2 ciri fitur tersebut tidak begitu baik dijadikan ciri fitur karena saling overlapping, perhatikan yang dikotak merah berikut
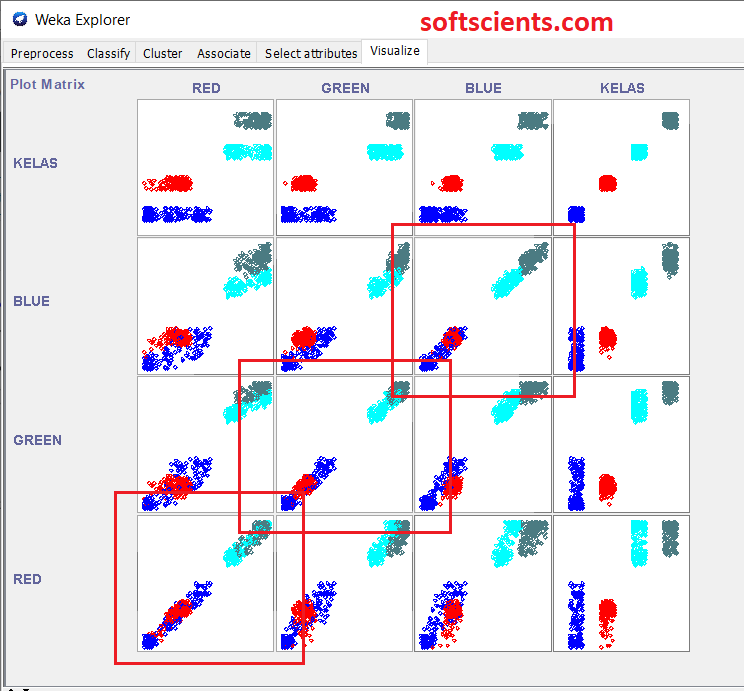
Dalam kata lain, ciri fitur RED dan GREEN hanya bisa membedakan 2 cluster saja, misalkan
- cluster A: didalamnya ada Apple Breaburn dan Apple Crimson Snow
- cluster B: didalamnya ada Apple Golden 2 dan Apple Golden 1
berbeda dengan ciri fitur BLUE lebih bagus lagi walau hanya bedakan 3 cluster saja, misalkan
- cluster A: didalamnya ada Apple Breaburn dan Apple Crimson Snow
- cluster B: didalamnya ada Apple Golden 2
- cluster C: dan Apple Golden 1
Memilih Algoritma
Dengan sudah melihat isi jeroan dataset tersebut, kita coba saja lakukan klasifikasi menggunakan RandomForest pada WEKA hasilnya sangat bagus sekali dengan 100% akurasi
=== Run information ===
Scheme: weka.classifiers.trees.RandomForest -P 100 -I 100 -num-slots 1 -K 0 -M 1.0 -V 0.001 -S 1
Relation: out-weka.filters.unsupervised.attribute.Remove-R1-weka.filters.unsupervised.attribute.Remove-R1
Instances: 636
Attributes: 4
RED
GREEN
BLUE
KELAS
Test mode: evaluate on training data
=== Classifier model (full training set) ===
RandomForest
Bagging with 100 iterations and base learner
weka.classifiers.trees.RandomTree -K 0 -M 1.0 -V 0.001 -S 1 -do-not-check-capabilities
Time taken to build model: 0.12 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0.08 seconds
=== Summary ===
Correctly Classified Instances 636 100 %
Incorrectly Classified Instances 0 0 %
Kappa statistic 1
Mean absolute error 0.0013
Root mean squared error 0.0166
Relative absolute error 0.3545 %
Root relative squared error 3.8445 %
Total Number of Instances 636
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Braeburn
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Crimson Snow
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Golden 1
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Golden 2
Weighted Avg. 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== Confusion Matrix ===
a b c d <-- classified as
164 0 0 0 | a = Apple Braeburn
0 148 0 0 | b = Apple Crimson Snow
0 0 160 0 | c = Apple Golden 1
0 0 0 164 | d = Apple Golden 2
Tapi bilamana menggunakan naive bayes? ternyata 98% akurasinya
=== Run information ===
Scheme: weka.classifiers.bayes.NaiveBayes
Relation: out-weka.filters.unsupervised.attribute.Remove-R1-weka.filters.unsupervised.attribute.Remove-R1
Instances: 636
Attributes: 4
RED
GREEN
BLUE
KELAS
Test mode: evaluate on training data
=== Classifier model (full training set) ===
Naive Bayes Classifier
Class
Attribute Apple Braeburn Apple Crimson Snow Apple Golden 1 Apple Golden 2
(0.26) (0.23) (0.25) (0.26)
===========================================================================================
RED
mean 123.7214 128.7028 175.6906 181.8305
std. dev. 13.7041 5.6491 9.8132 5.605
weight sum 164 148 160 164
precision 0.1399 0.1399 0.1399 0.1399
GREEN
mean 49.3069 52.3297 151.9758 173.8937
std. dev. 20.3565 4.4578 9.8751 5.5238
weight sum 164 148 160 164
precision 0.2646 0.2646 0.2646 0.2646
BLUE
mean 32.1088 41.535 75.858 91.2641
std. dev. 7.4508 1.6827 3.5042 3.5439
weight sum 164 148 160 164
precision 0.1346 0.1346 0.1346 0.1346
Time taken to build model: 0 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0.02 seconds
=== Summary ===
Correctly Classified Instances 626 98.4277 %
Incorrectly Classified Instances 10 1.5723 %
Kappa statistic 0.979
Mean absolute error 0.0131
Root mean squared error 0.074
Relative absolute error 3.5051 %
Root relative squared error 17.0898 %
Total Number of Instances 636
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.982 0.015 0.958 0.982 0.970 0.959 0.998 0.991 Apple Braeburn
0.953 0.006 0.979 0.953 0.966 0.956 0.997 0.994 Apple Crimson Snow
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Golden 1
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Apple Golden 2
Weighted Avg. 0.984 0.005 0.984 0.984 0.984 0.979 0.999 0.996
=== Confusion Matrix ===
a b c d <-- classified as
161 3 0 0 | a = Apple Braeburn
7 141 0 0 | b = Apple Crimson Snow
0 0 160 0 | c = Apple Golden 1
0 0 0 164 | d = Apple Golden 2
Bila ditilik lebih jauh, seharusnya
- aktual Apple Braeburn tapi 3 diantaranya salah prediksi menjadi Apple Crimson Snow
- aktual Apple Crimson Snow tapi 7 diantara salah prediksi menjadi Apple Braeburn
Hal ini sudah kita kemukakan bahwa 2 kelas tersebut memang overlapping koq ya wajar saja seperti itu di naive bayes!
Integrasi WEKA pada kode java
Bagi kalian pengguna bahasa java untuk develop aplikasi ataupun sebagai bahasa utama untuk analisis datanya, tentu tertarik integrasikan kecanggihan WEKA pada kode kalian! atau tetap menggunakan WEKA dengan menyimpan model tersebut https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/atau jika ingin integrasi weka pada java.
Tuning Model
Selain menggunakan teknik visualisasi dataset sebagai permulaan tuning model, maka dalam tingkat lanjut sudah memilih algoritma maka disitulah kalian melakukan tuning model menggunakan beragam paramater yang melekat pada algoritma tersebut, misalkan saja kalian
- menggunakan MLP – multi layer perceptron, kalian bisa setting jenis function, learning rate, atau jumlah node bahkan jumlah layer hidden
- bila menggunakan SVM – Support Vector Machine, kalia bisa setting jenis kernel function seperti gaussian, radial, polynomial
Menguji Kehandalan Model
Untuk menguji kehandalan model, bisa kalian gunakan teknik KFOLD, bisa kalian pelajari disini, disini, disini
Menguji Akurasi Model
Hemm, untuk menguji akurasi model bisa menggunakan teknik confusion matrix atau statik biasa, bisa kalian pelajari disini, disini, disini, disini, disini,
Gimana menurut kalian? lengkap ya https://softscients.com dalam menyajikan informasi mengenai data science!
Butuh konsultasi? kesini saja
Jika model sudah terpilih
Melalui contoh diatas, bisa kita pilih RandomForest sebagai model algoritma untuk klasifikasi, karena kita ingin membuat aplikasi yang bisa digunakan oleh mesin sortir. Kita perlu menyimpan model hasil pelatihan untuk digunakan kembali. Yuk kita koding saja,
Mulai dari dataset training dan testing, Berikut hasil perhitungan ciri fitur yang telah dilakukan oleh data engineer pada proses sebelumnya
Pelajari struktur table
Structure of fruit training.csv
Index | Column Name | Column Type |
-----------------------------------------
0 | NO | INTEGER |
1 | FILE | STRING |
2 | RED | DOUBLE |
3 | GREEN | DOUBLE |
4 | BLUE | DOUBLE |
5 | KELAS | STRING |
Structure of fruit testing.csv
Index | Column Name | Column Type |
-----------------------------------------
0 | NO | INTEGER |
1 | FILE | STRING |
2 | RED | DOUBLE |
3 | GREEN | DOUBLE |
4 | BLUE | DOUBLE |
5 | KELAS | STRING |
Menurut output diatas, terdiri dari 6 kolom yaitu
- NO
- FILE
- RED
- GREEN
- BLUE
- KELAS
Sesuai artikel sebelumnya, dataset tersebut mempunyai struktur
- ciri fitur yaitu nama kolom RED, GREEN, BLUE sedangkan
- kelas/target yaitu KELAS
Tuning Model untuk dataset training
Untuk menggunakan WEKA pada kode java, kalian bisa baca artikel disini, berikut potongan kode java untuk training dataset serta menyimpan model nya
Instances after_remove = LatihWEKA.filterInstance(file_training);
Classifier model = new RandomForest();
model.buildClassifier(after_remove); //train
Evaluation eval = new Evaluation(after_remove);
eval.evaluateModel(model,after_remove);
System.out.println(model);
System.out.println(eval.toClassDetailsString());
System.out.println(eval.toSummaryString());
System.out.println(eval.toMatrixString());
SerializationHelper.write("model terbaik.obj",model);
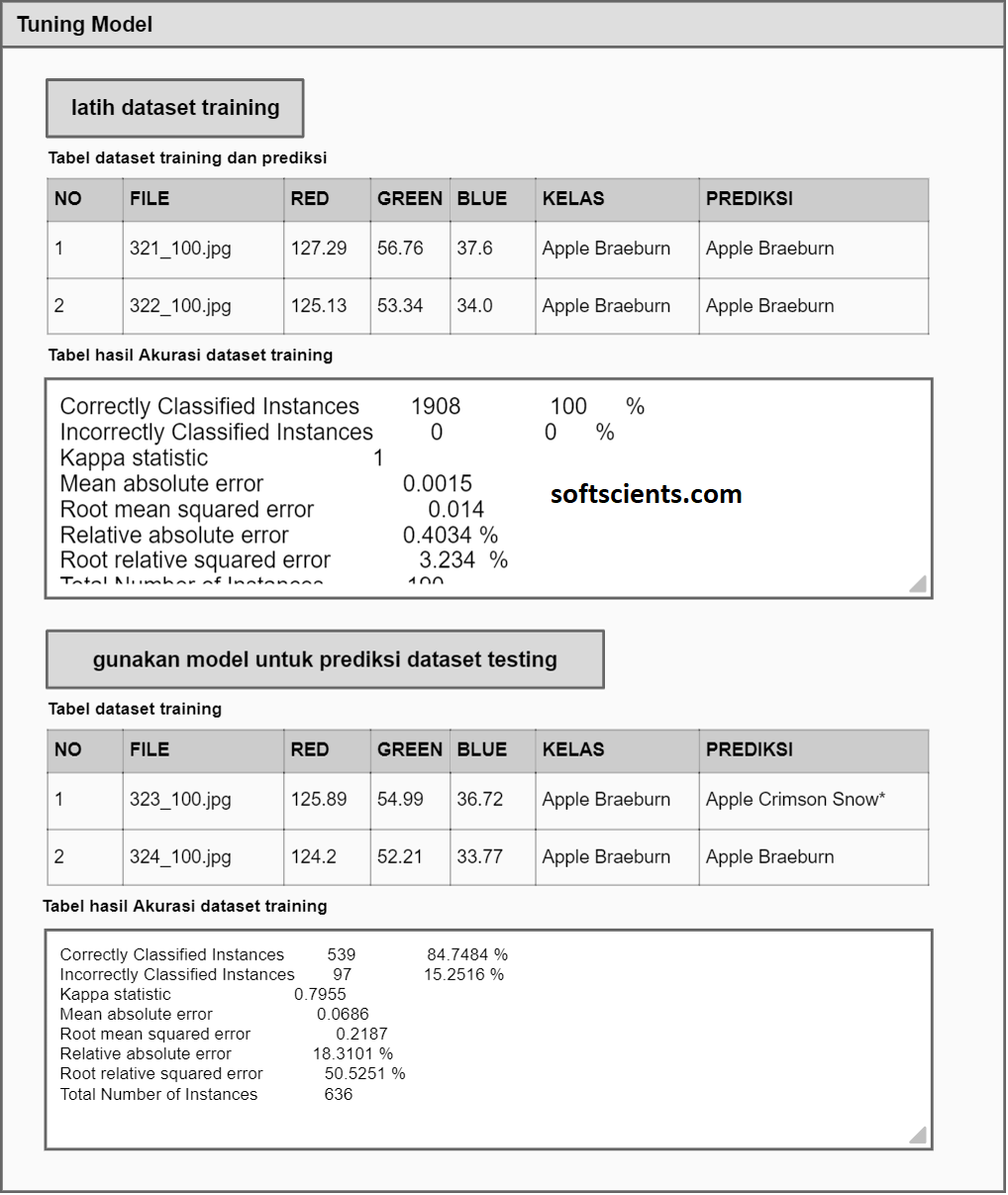
Output diatas adalah dari 1908 record akurasinya 100% tidak ada yang salah!
Correctly Classified Instances 1908 100 % Incorrectly Classified Instances 0 0 % Kappa statistic 1 Mean absolute error 0.0015 Root mean squared error 0.014 Relative absolute error 0.4034 % Root relative squared error 3.234 % Total Number of Instances 1908 === Confusion Matrix === a b c d <-- classified as 492 0 0 0 | a = Apple Braeburn 0 444 0 0 | b = Apple Crimson Snow 0 0 480 0 | c = Apple Golden 1 0 0 0 492 | d = Apple Golden 2
Model disimpan dengan nama model terbaik.obj, sebenarnya untuk tuning randomforest ada banyak paramater yang digunakan seperti
weka.classifiers.trees.RandomForest -P 100 -I 100 -num-slots 1 -K 0 -M 1.0 -V 0.001 -S 1
Kalian bisa baca tersendiri paramater apa saja yang perlu disetting di RandomForest
Menguji model menggunakan dataset testing
Model diatas tersebut kita gunakan kembali untuk melakukan prediksi! terhadap dataset testing, potongan kode nya yaitu
Instances after_remove2 = LatihWEKA.filterInstance(file_testing);
RandomForest cls = (RandomForest) weka.core.SerializationHelper.read("model terbaik.obj");
Evaluation eval_testing = new Evaluation(after_remove2);
eval_testing.evaluateModel(model,after_remove2);
System.out.println(cls);
System.out.println(eval_testing.toClassDetailsString());
System.out.println(eval_testing.toSummaryString());
System.out.println(eval_testing.toMatrixString());
Outputnya ternyata dari 636 record dataset testing mempunyai akurasi sebesar 84%
Correctly Classified Instances 539 84.7484 % Incorrectly Classified Instances 97 15.2516 % Kappa statistic 0.7955 Mean absolute error 0.0686 Root mean squared error 0.2187 Relative absolute error 18.3101 % Root relative squared error 50.5251 % Total Number of Instances 636 === Confusion Matrix === a b c d <-- classified as 164 0 0 0 | a = Apple Braeburn 93 55 0 0 | b = Apple Crimson Snow 0 0 156 4 | c = Apple Golden 1 0 0 0 164 | d = Apple Golden 2
hem…. hasilnya tidak begitu bagus sih, tapi cukuplah dengan hasil segitu. Langkah selanjutnya adalah model terbaik.obj bisa kalian gunakan deploy ke machine untuk bisa digunakan kembali menggunakan data asing
Pembuatan GUI
Biar lebih jelas, kita buatkan saja GUI seperti berikut untuk tuning model
Apa itu data asing?
Dataset yang kalian gunakan sebelumnya dipecah menjadi 2 yaitu terdiri dari dataset training dan testing, semuanya wajib diketahui dari awal mengenai ciri fitur dan kelasnya!
Ingat bahwa dataset diatas digunakan untuk tuning model sehingga wajib lengkap ciri fitur dan kelasnya sedangkan data asing merupakan
- data yang sama sekali baru,
- belum pernah digunakan
sehingga tugas komputer akan
- mengolah/menghitung ciri fitur serta
- melakukan prediksi kelas/target
jadi jangan bingung istilah data asing dan tidak perlu lagi diuji akurasi modelnya lagi karena aplikasi sudah tahap digunakan secara real dilapangan! karena kalau diuji akurasinya ya kalian wajib tahu data asing itu masuk kelas/target apa dulu (aktual), kemudian kalian bandingkan hasil prediksi komputer (prediksi)
GUI Produksi
Berikut rancangan GUI yang siap digunakan untuk data asing
ref:
https://towardsdatascience.com