

Pelanggan adalah raja itulah ungkapan klasik ketika berbisnis sehingga untuk mendapatkan pelanggan adalah tujuan utama pebisnis. Namun ada yang lebih sulit lagi yaitu mempertahankan pelanggan adalah hal yang berbeda. Bisnis kalian akan tertinggal jika tidak bisa merawat pelanggan. Jika hal itu terjadi, maka semua lambat laun akan mematikan bisnis bila semua pelanggan telah pergi.
Pelanggan yang telah pergi dikatakan dengan istilah customer churn. Menurut wikipedia Churn rate adalah ukuran jumlah orang atau benda yang masuk atau keluar dari suatu kelompok dalam jangka waktu tertentu. Istilah ini biasanya digunakan dalam konteks customer base sebagai persentase pelanggan yang meninggalkan supplier dalam jangka waktu tertentu. Hal ini menandai ketidakpuasan customer, tawaran lebih murah dari pesaing, pemasaran yang lebih baik oleh pesaing, atau penyebab lain. Singkatnya, customer churn adalah salah satu faktor terpenting yang harus terus dievaluasi oleh bisnis manapun, khususya bagi bisnis yang sedang berkembang.
Apa Itu Customer Churn Rate?
Contents
Customer churn rate merupakan persentase pelanggan yang berhenti menggunakan produk dan layanan bisnis selama jangka waktu tertentu. Cara mudah menghitung customer churn dengan membagi jumlah pelanggan yang hilang di akhir dengan jumlah pelanggan yang kita miliki di awal jangka waktu tersebut.
Misalnya, jika pada kuartal pertama tahun 2021 dengan 400 pelanggan dan diakhiri dengan 380 pelanggan, maka churn rate Anda adalah 5% karena Anda kehilangan 5% dari pelanggan Anda. Tentunya, sudah jelas kalau bisnis Anda harus menargetkan churn rate yang mendekati 0%.
Dengan menekan churn rate dan menjadikan pengalaman pelanggan sebagai prioritas utama. Tidak hanya jumlah pelanggan, kalian juga dapat menghitung churn rate dengan indikator lain, misalnya nilai bisnis yang hilang selama jangka waktu tertentu karena pelanggan tidak hanya membeli suatu satu jenis produk saja.
Mengapa Customer Churn Rate Sangat penting
Nampaknya kehilangan 5% kedengarannya tidak terlalu besar bukan? Faktanya, peningkatan retensi (pelanggan yang melakukan order kembali) sebanyak 5% dapat meningkatkan laba sampai sebesar 25%. Hal ini sangat masuk akal karena pelanggan existing sudah kenal baik dengan produk/layanan jasa sehingga repeat order akan menjadi sering /berkali-kali. Selain itu kalian pun dapat menghemat biaya operasional karena tidak perlu menghabiskan lebih banyak waktu dan uang untuk mempertahankan mereka.
Sebab-sebab Customer Churn Rate tinggi
Ada beberapa kategori yang umumnya menjadi penyebab customer churn, Namun biasanya customer churn meningkat ketika masa promosi habis. Berikut setidaknya ada 5 faktor yang mempengaruhi churn rate.
1. Harga
Secara umum harga sebuah produk/jasa yang mudah dilihat oleh pelanggan. Jika pelanggan menemukan solusi yang lebih murah untuk masalah mereka, sangat mungkin bagi mereka untuk beralih. Namun demikian harga bukan faktor mutlak, karena ada pepatah ada harga – ada rupa. Sehingga menjadi penting untuk menunjukkan kualitas produk/jasa sehingga mereka merasa bahwa produk/jasa akan sepadan dengan harganya.
2. Penyesuaian Produk/Pasar
Shifting produk/pasar yang tidak smooth / buruk adalah alasan umum mengapa pelanggan berhenti berbisnis dengan kalian, contohnya yang sedang hot saat ini berupa kebijakan pengguna Whatsapp yang baru. Penyampaian kebijakan baru yang terkesan memaksa kepada pelanggan mengakibatkan shifting ke aplikasi telegram dan signal. Hal ini menjadi contoh bagi kalian agar harus berhati-hati melakukan komunikasi terhadap pelanggan sehingga tidak menimbulkan kerancuan.
3. Pengalaman Pengguna
Jika pelanggan mendapatkan pengalaman yang kurang nyaman ketika sedang mengakses aplikasi, web, atau sekadar menghubungi akun bisnis WhatsApp Anda, mereka tidak akan segan untuk langsung melangkah pergi dari bisnis Anda. Untuk itu, Anda harus memberikan pengalaman pengguna yang nyaman demi mengurangi churn rate pada bisnis Anda.
4. Pengalaman Pelanggan
Pengalaman pelanggan terhubung dengan berbagai aspek bisnis mulai dari konten pemasaran, media sosial, sampai tim layanan pelanggan. Jika kalian tidak dapat memberikan pengalaman yang positif kepada pelanggan, maka siap-siaplah dengan perginya pelanggan setia.
Cara mengurangi Churn Rate
Setelah kita bahas mengenai faktor-faktor yang mempengaruhi churn rate, saya akan sajikan/rangkumkan beberapa faktor yang akan mengurangi churn rate diantaranya yaitu
1. Hargai Pelanggan
Komunikasi secara teratur adalah cara terbaik menghargai pelanggan. Dengan sikap yang proaktif saat berkomunikasi dengan pelanggan karena mereka ingin merasakan perhatian dari kalian. Caranya adalah Menjawab telepon, sms, email, media sosial dan layanan kontak pelanggan lainnya dengan cepat.
2. Puaskan Ekspektasi Pelanggan
Jangan PHP alias (pemberi harapan palsu) alias jangan berjanji jika tidak bisa mewujudkannya. Tetapkan ekspektasi yang realistis ataupun siap-siap memberikan beberapa alternatif jika suatu produk/jasa tersebut tidak ada/habis/rusak.
3. Dengarkan Keluhan Pelanggan
Hampir semua produk/jasa pasti ada keluhan dari pelanggan, maka hal yang paling mudah menangani keluhan pelanggan adalah dengan cara mendengarkannya dan jangan lupa untuk selalu berterima kasih kepada pelanggan atas semua jenis umpan balik (feedback) yang telah mereka berikan.
4. Fokus pada Pelanggan Terbaik Anda
Bagi sebagian besar bisnis, menyelesaikan churn berarti mengidentifikasi kumpulan pelanggan yang kemungkinan besar akan meninggalkan mereka lalu mengeluarkan segala daya dan upaya untuk mempertahankan mereka. Namun, Sunil Gupta, seorang profesor di Harvard Business School, merasa kalau strategi ini kurang efektif.
Daripada memberikan waktu dan sumber daya untuk mempertahankan semua pelanggan yang berada di ambang churn, Gupta merekomendasikan agar pebisnis memusatkan perhatian mereka pada pelanggan terbaik yang berada di ambang churn. Untuk menilai hal ini, kalian bisa menggunakan teknik RFM yang bisa kalian pelajari disini
5. Tawarkan Promo
Promo/gimmick/potongan harga merupakan hal bisa mempertahankan pelanggan. Tapi memberikan tawaran promo terus menerus akan menggerus laba bisnis, nah ada teknik yang kalian bisa gunakan, misalkan ketika mendekati akhir kontrak perjanjian jual beli yang memungkinkan kalau mereka tidak akan memperpanjang kontrak, maka kalian dapat memberikan diskon kepada mereka.
Langkah lain jika kalian sudah memprediksi kalau pelanggan akan pergi setelah menyadari kalau produk atau layanan kalian bukanlah yang mereka cari, berikan mereka intensif. Kemudian, buatlah fitur atau strategi baru supaya bisnis dapat memenuhi kebutuhan mereka.
Customer churn memang dapat merugikan bisnis kalian, terlebih jika kalian emang sengaja mengizinkannya. Oleh karena itu, ubah strategi bisnis sekarang dengan menerapkan beberapa strategi yang telah diuraikan di atas. Kita lanjutkan saja dengan melakukan studi kasus mengenai Customer Churn Prediction untuk memahami fenomena tersebut.
Tahapan Permodelan Churn Prediction
Hanif (2019) menyatakan ada empat tahap utama permodelan churn prediction yaitu
- Data pre-processing
- Feature Engineering and Selection.
- Modeling.
- Evaluation.
Tahapan Data Pre-Processing terdiri dari 4 tahap utama:
- Menentukan fitur prediktor (X) dan fitur label/target (Y). Fitur prediktor atau variabel bebas bisa berupa angka ataupun kategorikal.
- Pemeriksaan missing value di X dengan mengganti nilai yang hilang dengan suatu nilai yang diperoleh dari perhitungan statistik seperti rataan dan median. Dengan begitu, tidak ada informasi yang terbuang (akibat penghapusan baris) dan hasil analisis yang dihasilkan tetap valid.
- penanganan pencilan di X. Penanganan pencilan adalah penggantian nilai suatu objek yang dianggap menyimpang dari nilai-nilai lainnya pada suatu fitur, sehingga bisa menyebabkan bias. Salah satu cara penganganan pencilan adalah dengan menetapkan standar nilai 3 sigma, dimana amatan yang berada di luar batas μ+3σ (batas atas) atau μ–3σ (batas bawah), maka amatan tersebut harus digantikan dengan nilai sesuai batas atas atau batas bawah. Dengan begitu, efek bias akibat adanya pencilan dapat diminimalisir.
- split dataset train-test untuk X & Y. Pemisahan data train-test dilakukan dengan membagi secara acak dataset awal menjadi dua bagian dengan proporsi yang berbeda. Bisa menggunakan proporsi 80:20 ataupun 70:30
Feature Engineering and Selection
Feature Engineering adalah tahap mengubah nilai suatu variabel/fitur menjadi suatu nilai yang baru. al ini dilakukan dikarenakan variabel/fitur yang digunakan dalam modeling memiliki satuan yang berbeda-beda, sehingga jika tidak di standardisasi maka akan berdampak pada akurasi model yang dihasilkan atau biasa disebut dengan normalisasi data
Feature Selection adalah proses mereduksi variabel/fitur dengan menghilangkan fitur yang tidak ada hubungannya ataupun berkorelasi rendah. Bisa menggunakan PCA
Modeling
Modeling yaitu membuat model prediksi/klasifikasi menggunakan algoritma tertentu dengan menggunakan data training, yang kemudian divalidasi dengan menggunakan data testing. Secara umum model akan melakukan prediksi/klasifikasi seperti
- Model credit scoring untuk mengklasifikasikan good debtors dan bad debtors, sehingga bank mampu meminimalisir risiko gagal bayar dengan menolak pegajuan kredit dari bad debtors.
- Model churn prediction mengklasifikasikan pengguna yang akan churn dan tidak churn di masa mendatang, sehingga perusahaan telco mampu membuat kebijakan dan strategi untuk meretensi pelanggan yang akan churn.
- Model cross-sell & up-sell mengklasifikasikan pelanggan menajadi high propensity customer dan low propensity customer, sehingga tim pemasaran mampu membuat targeted campaign kepada high-propensity customer dengan peluang terjadinya transaksi cross-sell & up-sell yang lebih tinggi. Seperti menggunakan teknik RFM
Berbagai macam algoritma prediksi/klasifikasi mulai dari
- Logsitic Regression,
- K-Nearest Neighbor,
- Decision Tree,
- Support Vector Machine,
- Naive Bayes,
- Random Forest,
- Gradient Boosting, hingga
- Neural Network dapat diterapkan untuk membangun model prediktif
Evaluation
Evaluasi yang digunakan menggunakan confussion matrix
Studi Kasus Customer Churn Prediction
Pada kasus ini, saya akan menggunakan bahasa R saja agar relatif mudah untuk digunakan. R adalah salah satu bahasa utama dalam ekosistem data science. Ini terutama dirancang untuk komputasi statistik dan grafik. R memudahkan penerapan teknik statistik secara efisien dan karenanya merupakan pilihan yang sangat baik untuk tugas pembelajaran mesin/machine learning.
Dalam artikel ini, kita akan membuat random forest model untuk memecahkan masalah umum pembelajaran mesin: prediksi churn/churn prediction.
customer churn adalah masalah penting untuk setiap bisnis. Sambil mencari cara untuk memperluas portofolio pelanggan, bisnis juga berfokus pada mempertahankan pelanggan yang sudah ada. Oleh karena itu, sangat penting untuk mempelajari alasan mengapa pelanggan yang sudah ada malah pergi.
Dataset
Dataset yang kita gunakan dari www.kaggle.com berupa credit card customers – https://www.kaggle.com/sakshigoyal7/credit-card-customers. Kami akan menggunakan perpustakaan randomForest untuk R. Langkah pertama adalah menginstal dan mengimpor perpustakaan.
Seorang manajer di bank merasa terganggu dengan semakin banyaknya pelanggan yang meninggalkan layanan kartu kredit mereka. Mereka akan sangat menghargai jika seseorang dapat memprediksi untuk mereka siapa yang akan mengalami churn sehingga mereka dapat secara proaktif pergi ke pelanggan untuk memberikan mereka layanan yang lebih baik dan mengubah keputusan pelanggan ke arah yang berlawanan.
Sekarang, kumpulan data ini terdiri dari 10.000 pelanggan yang menyebutkan usia, gaji, status_kawinan, batas kartu kredit, kategori kartu kredit, dll
- “CLIENTNUM”,
- “Attrition_Flag”,
- “Customer_Age”,
- “Gender”,
- “Dependent_count”,
- “Education_Level”,
- “Marital_Status”,
- “Income_Category”,
- “Card_Category”,
- “Months_on_book”,
- “Total_Relationship_Count”,
- “Months_Inactive_12_mon”,
- “Contacts_Count_12_mon”,
- “Credit_Limit”,
- “Total_Revolving_Bal”,
- “Avg_Open_To_Buy”,
- “Total_Amt_Chng_Q4_Q1”,
- “Total_Trans_Amt”,
- “Total_Trans_Ct”,
- “Total_Ct_Chng_Q4_Q1”,
- “Avg_Utilization_Ratio”,
- “Naive_Bayes_Classifier_Attrition_Flag_Card_Category_Contacts_Count_12_mon_Dependent_count_Education_Level_Months_Inactive_12_mon_1”,
- “Naive_Bayes_Classifier_Attrition_Flag_Card_Category_Contacts_Count_12_mon_Dependent_count_Education_Level_Months_Inactive_12_mon_2”
Dari 23 kolom diatas, maka ada yang kita harus remove/hilangkan yaitu font yang diberi warna merah. Kolom Attrition_Flag berisi 2 jenis yaitu Existing customer (Active) or Attrited Customer (Inactive).
Ekplorasi Data
Tidak lengkap bila rasanya kita melakukan eksplorasi data, hal yang paling mudah yaitu dengan bentuk visualisasi 2 dimensi bila data tersebut hanya terdiri dari 2 kelas atapun 3 dimensi bila 3 kelas. Misalkan kita akan eksplorasi data berdasarkan Gender
library(dplyr)
library(ggplot2)
churn = read.csv('BankChurners.csv')
churn$Attrition_Flag=factor(churn$Attrition_Flag,levels = churn$Attrition_Flag)
gender = churn %>% select(Gender,Attrition_Flag) %>% group_by(Gender) %>% summarise(frek=n())
p<-ggplot(data=gender, aes(x=Gender, y=frek)) +
geom_bar(stat="identity") +
labs(title = "Distribusi Existing dan Attrired",
subtitle = "Berdasarkan Gender",
caption = "Data source: https://softscients.com",
x = "Gender", y = "Frekuensi",
tag = "Hasil Ekplorasi Data")
p
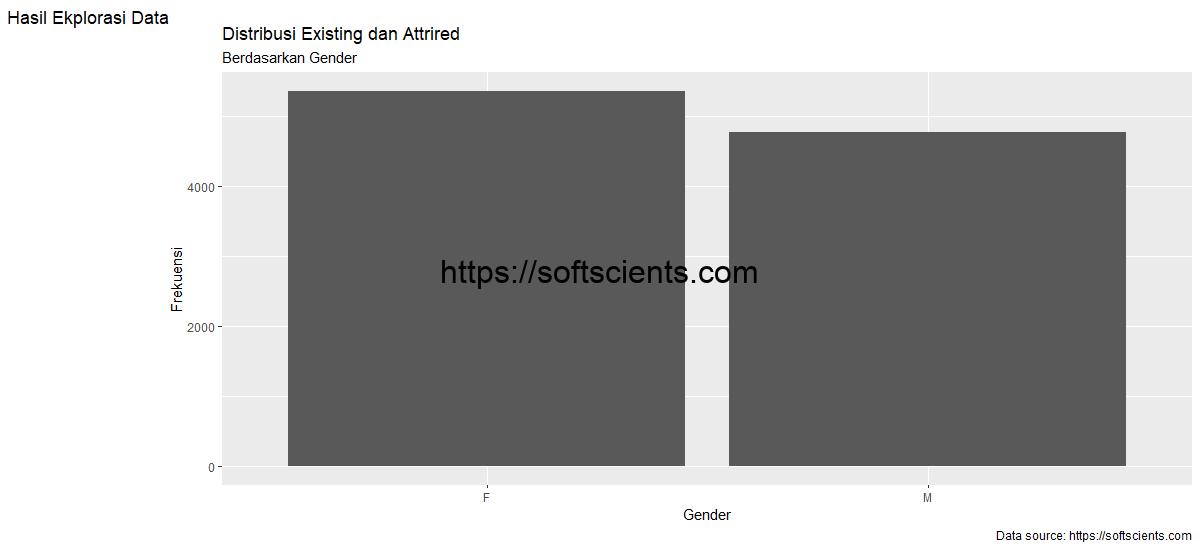
Ternyata konsumen kartu kredit paling banyak dari female karena hoby belanja. Kita eksplor lagi dari Female dan Male
gender_female = churn %>% select(Gender,Attrition_Flag)%>% group_by(Attrition_Flag,Gender) %>% summarise(frek=n())
gender_female
p<-ggplot(data=gender_female, aes(fill=Attrition_Flag,x=Gender, y=frek)) +
geom_bar(stat="identity") +
labs(title = "Distribusi Existing dan Attrired",
subtitle = "Berdasarkan Gender",
caption = "Data source: https://softscients.com",
x = "Attrition_Flag", y = "Frekuensi",
tag = "Hasil Ekplorasi Data")
p

Ternyata baik male dan female mempunyai proporsi yang sama yaitu adanya Attrited Customer.
Memilih Algoritma
Setelah kalian melihat data diatas dengan beberapa jenis data
Install Library Random Forest
Kita akan menggunakan algoritma randomforest, bagi yang belum install di R, kalian bisa melakukan install dengan cara berikut
install.packages("randomForest")
library(randomForest)
Droping Kolom yang tidak digunakan
Beberapa kolom bersifat redundan atau sangat berkorelasi dengan kolom lain. Jadi, kami akan droping 7 kolom.
churn2 <- churn[-c(1,3,10,16,19,22,23)]
Kita lihat nama-nama columns yang akan digunakan
names(churn2)
hasil
'Attrition_Flag''Gender''Dependent_count''Education_Level''Marital_Status''Income_Category''Card_Category''Total_Relationship_Count''Months_Inactive_12_mon''Contacts_Count_12_mon''Credit_Limit''Total_Revolving_Bal''Total_Amt_Chng_Q4_Q1''Total_Trans_Amt''Total_Ct_Chng_Q4_Q1''Avg_Utilization_Ratio'
Kolom attrition_flag adalah variabel target yang menunjukkan apakah pelanggan pergi (yaitu meninggalkan perusahaan). Kolom yang tersisa memuat informasi tentang nasabah dan aktivitas mereka dengan bank.
Menentukan Kolom Target
Langkah selanjutnya adalah membagi dataset menjadi subset train dan test. Saya akan membuat partisi dan menggunakannya untuk membagi data. Sebelum memisahkan dataset, kita perlu panggil function factor variabel target (Attrition_Flag) sehingga model mengetahui bahwa ini adalah tugas klasifikasi/targetnya dengan nilai 0.8 yang berarti 80% data akan saya masukan sebagai data training, sedangkan sisanya sebagai data testing.
Untuk mengubah data menjadi sebuah factor() cukup ketikan kode berikut
churn2$Attrition_Flag = as.factor(churn2$Attrition_Flag)
Split dataset train dan test
Kemudian spliting data, saya menggunakan random seed (42)
set.seed(42) train <- sample(nrow(churn2), 0.8*nrow(churn2), replace = FALSE) train_set <- churn2[train,] test_set <- churn2[-train,]
Membuat Random Forest Model
Langkah selanjutnya adalah membuat random forest model dan melatihnya.
model_rf <- randomForest(Attrition_Flag ~ ., data = train_set, importance = TRUE)
Kita membuat random forest model dan menunjukkan variabel target. Titik setelah operator tilde (~) memberi tahu model bahwa semua kolom lain digunakan dalam pelatihan sebagai variabel independen. Hasil dari Customer Churn Prediction yaitu
Call:
randomForest(formula = Attrition_Flag ~ ., data = train_set, importance = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 3
OOB estimate of error rate: 5.62%
Confusion matrix:
Attrited Customer Existing Customer class.error
Attrited Customer 951 347 0.26733436
Existing Customer 108 6695 0.01587535
Jumlah tree yang digunakan di random forest adalah 500 secara default. Kita bisa mengubahnya menggunakan parameter ntree.
Metrik kritis untuk evaluasi adalah estimasi OOB (Out of bag) dari tingkat kesalahan. Saya ingin menjelaskan secara singkat bagaimana algoritma random forest bekerja sebelum membahas secara rinci tentang perkiraan kesalahan OOB.
Random forest menggunakan bootstrap sampling yang berarti memilih sampel secara acak dari data pelatihan dengan penggantian. Setiap sampel bootstrap berisi sampel acak dari seluruh set data. Pengamatan yang tidak ada dalam sampel bootstrap disebut sebagai data out of bag. Untuk mendapatkan evaluasi model yang tidak bias dan lebih akurat, digunakan out of bag error.
Tingkat kesalahan OOB adalah 5,62% yang berarti akurasi model sekitar 95%. Untuk mengevaluasi model pada set pengujian, pertama-tama kita bisa membuat prediksi.
predTest <- predict(model_rf, test_set, type = "class") mean(predTest == test_set$Attrition_Flag)
hasil
0.94471865745311
Kita membandingkan prediksi dan variabel target dari set pengujian (Attrition_Flag) dan mengambil mean. Akurasi klasifikasi model pada set tes adalah 93,4% yang sedikit lebih rendah dari pada akurasi pada dataset train. Kita juga dapat menggenerate confussion matrix dengan perintah berikut
table(predTest, test_set$Attrition_Flag)
hasil
predTest Attrited Customer Existing Customer Attrited Customer 238 21 Existing Customer 91 1676
Kalian bisa menggunakan beberapa algoritma atau melakukan penyetelan hyperparameter adalah bagian penting dari pembuatan model, terutama untuk model yang kompleks. Misalnya, mengubah jumlah tree, the maximum depth. Nah Penyetelan hyperparameter membutuhkan pemahaman yang komprehensif tentang hyperparameter suatu algoritma sehingga yang sudah pernah bahas disini, bahwa kalian harus paham statistika dan matematika.