

Backward dan Step Optimizer – Tensor sebagai tipe data yang dioperasikan oleh library pytorch dan tensorflow merupakan core engine yang didalamnya sudah ada kemudahan dalam melakukan operasi derivatif biasa dikenal dengan operasi turunan serta perbaikan gradient. Operasi Apa itu Gradient Descent-Machine Learning? yang telah dibahas sebelumnya masih menggunakan cara manual dengan menggunakan operasi matematika empiris. Operasi gradient descent sebenarnya sudah dibungkus secara rapi pada Pytorch dengan memanfaatkan method step optimizer serta backward untuk derivatif.
Operasi Backward
Mari kita coba dengan persamaan matematika  .
.
Berapa nilai  bila
bila  ?
?
Sesuai persamaan berikut didapatkan untuk turunan fungsi pertama / derivatif nya yaitu  .
.
Sehingga ketika maka  . Mari kita coba dengan tensor saja pada PyTorch. Berikut kode yang digunakan
. Mari kita coba dengan tensor saja pada PyTorch. Berikut kode yang digunakan
import torch import torch.nn as nn x = torch.ones(1, requires_grad=True) y = x**2+x-6 y.backward() #hitung gradient print(x.grad)
hasilnya yaitu 3.
Operasi Step Optimizer
Kalian masih ingat arti dari gradient descent? untuk mencari titik minimum global dengan teknik iterasi?  . Yuk kita coba sesuai rumus tersebut dengan nilai
. Yuk kita coba sesuai rumus tersebut dengan nilai  sebagai berikut
sebagai berikut
hasil = x - 0.001*x.grad print(hasil)
hasilnya
tensor([0.9970], requires_grad=True)
langkah diatas sebenarnya cukup menggunakan kode berikut
optim = torch.optim.SGD([x], lr=0.001) optim.step() print(x)
Bila kita lakukan iterasi terus-menerus, kita akan mendapatkan nilai titik minum sebagai berikut (saya pakai learning rate = 0.15 agar lebih cepat konvergen)
import numpy as np
import torch
a = np.array([1],dtype=np.float32) #tebakan awal x= 1
for i in range(0,100):
x = torch.tensor(a,requires_grad=True)
y = x**2+x-6
y.backward()
optim = torch.optim.SGD([x],lr=0.15)
optim.step()
print(i,x) #akan menuju 0.5
a = x.detach().numpy()
output x akan mendekati -0.5
0 tensor([0.5500], requires_grad=True) 1 tensor([0.2350], requires_grad=True) 2 tensor([0.0145], requires_grad=True) 3 tensor([-0.1399], requires_grad=True) 4 tensor([-0.2479], requires_grad=True) 5 tensor([-0.3235], requires_grad=True) 6 tensor([-0.3765], requires_grad=True) 7 tensor([-0.4135], requires_grad=True) 8 tensor([-0.4395], requires_grad=True) 9 tensor([-0.4576], requires_grad=True) 10 tensor([-0.4703], requires_grad=True) 11 tensor([-0.4792], requires_grad=True) 12 tensor([-0.4855], requires_grad=True) 13 tensor([-0.4898], requires_grad=True) 14 tensor([-0.4929], requires_grad=True) 15 tensor([-0.4950], requires_grad=True) 16 tensor([-0.4965], requires_grad=True) 17 tensor([-0.4976], requires_grad=True) 18 tensor([-0.4983], requires_grad=True) 19 tensor([-0.4988], requires_grad=True) 20 tensor([-0.4992], requires_grad=True) 21 tensor([-0.4994], requires_grad=True) 22 tensor([-0.4996], requires_grad=True) 23 tensor([-0.4997], requires_grad=True) 24 tensor([-0.4998], requires_grad=True) 25 tensor([-0.4999], requires_grad=True) 26 tensor([-0.4999], requires_grad=True) 27 tensor([-0.4999], requires_grad=True) 28 tensor([-0.5000], requires_grad=True) 29 tensor([-0.5000], requires_grad=True) 30 tensor([-0.5000], requires_grad=True) 31 tensor([-0.5000], requires_grad=True)
Bila kita memasukan x = -0.5 atau  akan kita masukan ke persamaan
akan kita masukan ke persamaan
![\[y(x) = x^{2}+x-6\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-c5d6c1bbe9fdbe5f97e2dbe20476a982_l3.png "Rendered by QuickLaTeX.com")
menghasilkan nilai  . Yuk kita gambar langsung saja, kalian bisa melihat nilai global minimum nya
. Yuk kita gambar langsung saja, kalian bisa melihat nilai global minimum nya
dari operasi diatas, kalian sudah bisa tahu dasar cara kerja neural network di pytorch. Yup persamaan diatas tidak digunakan yang akan diganti dengan fungsi pembelajaran seperti sigmoid, ReLU, tansig. Function pembelajaran tersebut haruslah bisa di turunkan/derivatif dengan melibatkan fungsi loss seperti MSE. Untuk lebih jelasnya kalian bisa baca Linear Regression dengan Konsep Gradient Descent
Penerapan MLP
Kalian masih ingat donk operasi Mengenal Operasi Linear, Bobot, dan Bias pada Algoritma CNN yang merupakan operasi dot matrix antar  . Kita akan membuat neural network sederhana yang terdiri dari beberapa layer menggunakan 4 record yang setiap record punya 2 ciri fitur atau disebut dengan kasus logika Boolean XOR.
. Kita akan membuat neural network sederhana yang terdiri dari beberapa layer menggunakan 4 record yang setiap record punya 2 ciri fitur atau disebut dengan kasus logika Boolean XOR.
x2 = torch.tensor([
[1.0,1.0],
[1.0,0.0],
[0.0,0.1],
[0.0,0.0]
],requires_grad =True)
target2 = torch.tensor([[1.0],[0.0],[0.0],[1.0]],requires_grad =True)
Arsitektur yang kita gunakan, saya pilih menggunakan 3 layer yaitu
- self.layer1 = nn.Linear(2,10) artinya yaitu input 2, output 10
- self.layer2 = nn.Linear(10,5) artinya yaitu input 10, output 5
- self.layer3 = nn.Linear(5,1) artinya yaitu 5 input, output 1
Kalau saya gambarkan dalam bentuk node Neural Network Backpropagation menggunakan tools http://alexlenail.me/NN-SVG/index.html

Adapun untuk fungsi aktifasi yang digunakan yaitu
- hidden #1 ke hidden #2 menggunakan fungsi aktifasi ReLU
- hidden #2 ke hidden #3 menggunakan fungsi aktifasi ReLU
- hidden #3 ke output menggunakan fungsi aktifasi sigmoid sesuai output yang digunakan yaitu 0 dan 1 sehingga nanti diharapkan akan mendekati 0 dan 1
Untuk membuat neural network backpropagation maka kita akan extend dari class nn.Module, misalkan kita beri nama Net2 namun yang wajib kalian perhatikan yaitu 2 method/function penting yaitu __init__ dan forward()
class Net2(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(2,10)
self.layer2 = nn.Linear(10,5)
self.layer3 = nn.Linear(5,1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU()
def forward(self,x):
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
x = self.relu(x)
x = self.layer3(x)
x = self.sigmoid(x)
return x
Langkah selanjutnya yaitu membuat instance objek dari model diatas
model2 = Net2()
membuat function gradient descent
optimizer = torch.optim.SGD(model2.parameters(), lr = 0.01)
serta membuat loss function yang merupakan fungsi objektif yang dijadikan target agar setiap iterasi harus mengecil nilainya. Kita gunakan function MSE saja. MSE inilah yang akan di derifativ kan seperti pada contoh Tensorflow 2.0-Linear Regression bagian 3 nanti Tensor akan melakukan derivatif terhadap MSE
loss_fcn = nn.MSELoss()
Selain itu kita butuh visualisasi mengenai pergerakan error MSE per epoch, kita butuh pandas dan matplotlib
from matplotlib import pyplot as plt import pandas as pd
bila sudah semuanya! kita buat iterasi yang didalamnya ada backward dan step optimizer
list_err = list()
for i in range(0,100000):
optimizer.zero_grad()
prediksi = model2(x2)
loss = loss_fcn(prediksi,target2)
loss.backward()
optimizer.step()
list_err.append(loss.item())
if(i%100)==0:
print("Epoch {: >8} Loss: {}".format(i, loss.item()))
if(loss.item()<=0.001):
break
print(prediksi)
p = pd.DataFrame(list_err)
p.plot()
arti kode diatas yaitu akan dilakukan iterasi sebanyak 100 ribu kali dan akan berhenti jika MSE < 0.001. Berikut pergerakan MSE setiap epoch yang terhenti pada 40ribu

sesuai hasil yang didapatkan yaitu mendekati 0 dan 1
print(prediksi)
tensor([[0.9850],
[0.0069],
[0.0446],
[0.9583]], grad_fn=<SigmoidBackward>)
Perhatikan cara meletakan perintah backward() diatas yang artinya setiap 1 epoch (4 record) akan dilakukan optimizer dengan kode berikut yang setiap iterasi ( 1 record) akan dilakukan optimizer.
model2 = Net2()
optimizer = torch.optim.SGD(model2.parameters(), lr = 0.01)
target2 = torch.tensor([[1.0],[0.0],[0.0],[1.0]],requires_grad =True)
x2 = torch.tensor([
[1.0,1.0],
[1.0,0.0],
[0.0,0.1],
[0.0,0.0]
],requires_grad =True)
list_err = list()
for idx in range(0,50000):
for input, target in zip(x2, target2):
optimizer.zero_grad() # zero the gradient buffers
output = model2(input)
loss = loss_fcn(output, target)
loss.backward()
optimizer.step() # Does the update
list_err.append(loss.item())
if idx % 100 == 0:
print("Epoch {: >8} Loss: {}".format(idx, loss.item()))
if(loss.item()<=0.001):
break
print(prediksi)
p = pd.DataFrame(list_err)
p.plot()
ternyata menghasilkan error iterasi yang berbeda! yaitu hanya 17.5 ribu epoch saja sudah berhenti mirip pelana kuda yaitu naik tajam terus kemudian turun drastis mencapai konvergen. Saya sudah melakukan uji coba berkali-kali tetap hasilnya sama grafiknya. Silahkan kalian yang bisa menggunakan metode dibawah ini (biasa disebut 1 batch)
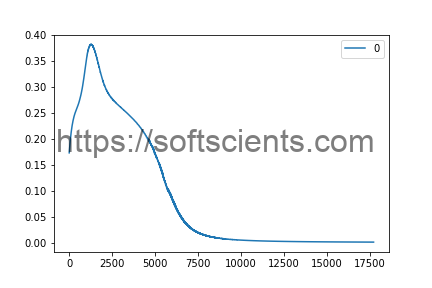
Demikian pembahasan mengenai Backward dan Step Optimizer pada PyTorch semoga kalian bisa paham cara kerja neural network backpropagation
ref: