

— Uji Stasioneritas Data — Dalam analisis time series hal yang perlu diperhatikan yaitu stationary data. Kita berangkat terlebih dahulu mengenai time series yang berarti setiap data mempunyai domain waktu atau dipengaruhi oleh waktu. Setidaknya ada beberapa plot time series seperti konstan (stationary), trend, seaosonal, dan cyclic. Time series digunakan untuk forecasting, nah ada satu metode forecasting yaitu ARIMA yang mengharuskan data tersebut bersifat stationary – konstan – stasioner.
Data stasioner adalah data yang menunjukkan mean, varians dan autovarians (pada variasi lag) tetap sama pada waktu kapan saja data itu dibentuk atau dipakai, artinya dengan data yang stasioner model time series dapat dikatakan lebih stabil. Apabila data yang digunakan dalam model ada yang tidak stasioner.
Tulisan ini akan dibagi menjadi 3 bagian yaitu pengertian stationary – konstan – stasioner, deteksi, serta mengubah data tersebut agar stationary – konstan – stasioner. Nanti kita akan menggunakan software seperti R/RStudio dan SPSS.
Pengertian stationary – konstan – stasioner
Contents
Data stasioner adalah sekumpulan data dinyatakan stasioner jika nilai rata-rata dan varian dari data time series tersebut tidak mengalami perubahan secara sistematik sepanjang waktu, atau sebagian ahli menyatakan rata-rata dan variannya konstan (nachrowi dan haridus usman, 2006). Kalian bisa melihat jenis plot time series berikut untuk mengetahui mengenai stasioner data
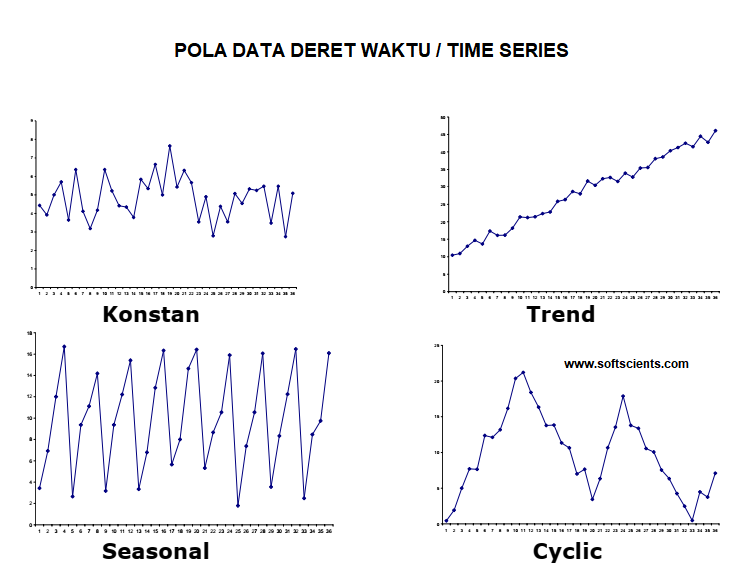
Data bersifat stasioner akan tampil acak tapi tetap ditengah/mean nya berbeda dengan data seasonal yang saling menyimpang jauh membentuk sebuah lembah dan gunung. Setelah kita mengetahui tampilan grafik stasioner, kita lanjut ke deteksi stasioner data
Uji Stasioneritas Data Dick Fuller
Untuk mnguji stasioneritas data, kita akan buat contoh dataset, data ini adalah data kelahiran bayi perhari daily-total-female-births, Yuk kita lihat plot datanya, oiya saya menggunakan R/RStudio buat ploting data biar gampang, nanti kalian bisa menggunakan excel koq. Berikut contoh data stasioner
library(dplyr)
library(ggplot2)
library(scales)
dat = read.csv('daily-total-female-births.csv')
dat$Date <- as.Date(dat$Date,format="%Y-%m-%d")
plot(dat$Births,type='l')
# (sengaja saya hapus tidak pakai ggplot biar nggak kebanyakan kode)

atau menggunakan SPSS juga bagus

dari plot diatas akan nampak bahwa data tersebut stationer.
Kita akan membandingkan antara contoh data stasioner diatas dengan non stasioner berikut yang diambil dari https://data.transportation.gov/api/views/xgub-n9bw/rows.csv?accessType=DOWNLOAD. Data tersebut adalah data penumpang harian sehingga datanya sangat banyak sekali. Saya akan olah saja yaitu dengan teknik pivot/aggregasi. Data akan diolah terlebih dahulu agar dijumlah perbulan saja. Berikut contoh snipet datasetnya
year month total_bulan tanggal <chr> <chr> <int> <date> 1 1990 01 6271648 1990-01-01 2 1990 02 5608228 1990-02-01 3 1990 03 7261485 1990-03-01 4 1990 04 6666438 1990-04-01 5 1990 05 6684581 1990-05-01 6 1990 06 7629021 1990-06-01 7 1990 07 8677938 1990-07-01 8 1990 08 9100434 1990-08-01 9 1990 09 7123752 1990-09-01 10 1990 10 6632612 1990-10-01
Bagi kalian yang suka menggunakan SPSS tentu butuh software tambahan seperti excel, tidak seperti R/RStudio maka proses aggregasi data sangat mudah.
library(dplyr)
library(ggplot2)
library(scales)
dat = read.csv('International_Report_Passengers.csv')
dat = dat %>% select(data_dte,Total) #ambil kolom date_dte dan Total saja
dat = dat %>% rename(date = data_dte) %>% rename(total = Total) #rename kolom
dat$date <- as.Date(dat$date,format="%m/%d/%Y") #ubah jadi format tanggal
#lakukan proses aggregasi dengan melakukan split bulan dan tahun
dat = dat %>%
mutate(month = format(date, "%m"), year = format(date, "%Y")) %>%
group_by(year,month) %>%
summarise(total_bulan = sum(total))
#merging
dat2 = dat%>%mutate(tanggal=as.Date(paste(1,month,year,sep='/'),format='%d/%m/%Y'))
plot(dat2$total_bulan,type='l')
# (sengaja saya hapus tidak pakai ggplot biar nggak kebanyakan kode)
Kita lihat data time series nya mengandung trend

Namun bila kalian ingin menampilkan dalam SPPS, simpan saja variabel dat2 kedalam format CSV
write.csv(dat2,'data olah passenger.csv')
Berikut tampilan data time series non stasioner di SPSS
 Uji stasioneritas data kelahiran bayi
Uji stasioneritas data kelahiran bayi
Namun demikian melihat plot data akan bersifat subjeksifitas, oleh hal tersebut kita membutuhkan uji stasioneritas data time series menggunakan analisis Uji Stasioneritas Augmented Dickey–Fuller (ADF). Langsung saja kita akan menguji uji stasioneritas data time series pada dataset kelahiran diatas menggunakan package tseries.
Mari kita uji untuk data kelahiran bayi perhari (menurut plot grafik adalah stasioner)
library(tseries) adf.test(dat$Births)
untuk dataset kelahiran bayi harian didapatkan hasil berikut
Augmented Dickey-Fuller Test data: dat$Births Dickey-Fuller = -11.491, Lag order = 1, p-value = 0.01 alternative hypothesis: stationary
Hipotesis untuk ADF yaitu
H0 : data deret waktu tidak stasioner
H1 : data deret waktu stasioner
Dengan keterangan sebagai berikut
- jika p-value > siginifikan, maka HO diterima maka dapat disimpulkan data tidak stasioner.
Pada contoh diatas dihasilkan p-value = 0.01 < 0.05 artinya H0 ditolak sehingga data kelahiran bayi adalah data stasioner.
Uji stasioneritas data air passenger
Kita akan coba uji stasioneritas data air passenger diatas, kita cek dulu
adf.test(dat2$total_bulan)
hasilnya
Augmented Dickey-Fuller Test data: dat2$total_bulan Dickey-Fuller = -5.3722, Lag order = 7, p-value = 0.01 alternative hypothesis: stationary
hemm ternyata tidak masuk akal! coba kita buat lag/frekuensinya 12 yang artinya setiap 12 bulan akan terjadi trend naik/berulang
adf.test(dat2$total_bulan,k=12)
hasilnya
Augmented Dickey-Fuller Test data: dat2$total_bulan Dickey-Fuller = -1.136, Lag order = 12, p-value = 0.9158 alternative hypothesis: stationary
Pada contoh diatas dihasilkan p-value = 0.9158> 0.05 artinya H0 diterima sehingga data air passenger adalah data non stasioner yang berulang mengandung tren setiap frekuensi 12
adf.test dengan nilai lag yang berbeda-beda
hemm kalian tentu penasaran, kenapa nilai lag pada adf.test harus disetting? yuk kita coba nilai lag dimulai dari 1 sampai 12 untuk data air passenger akan menghasilkan nilai p-value berikut
hasil = data.frame()
for(k in c(1:12)){
model = adf.test(dat2$total_bulan,k=k)
buffer = data.frame(lag=k,model$p.value)
hasil = rbind(hasil,buffer)
}
hasil
hasilnya
lag model.p.value 1 1 0.01000000 2 2 0.01000000 3 3 0.01000000 4 4 0.01000000 5 5 0.01000000 6 6 0.01000000 7 7 0.01000000 8 8 0.07347634 9 9 0.18301770 10 10 0.99000000 11 11 0.99000000 12 12 0.91583079
dapat disimpulkan bahwa data air passenger mulai tidak stasioner itu pada lag = 10 (mengingat data air passenger tersaji dalam bentuk bulanan akan nampak pada bulan ke 10 setiap bulannya).
Hal ini berbeda dengan data kelahiran bayi dengan lag berapun akan senantiasa sama, karena data tersebut stationer, mari kita coba
hasil = data.frame()
for(k in c(1:12)){
model = adf.test(dat$Births,k=k)
buffer = data.frame(lag=k,model$p.value)
hasil = rbind(hasil,buffer)
}
hasil
hasilnya
lag model.p.value 1 1 0.01 2 2 0.01 3 3 0.01 4 4 0.01 5 5 0.01 6 6 0.01 7 7 0.01 8 8 0.01 9 9 0.01 10 10 0.01 11 11 0.01 12 12 0.01
jadi jangan bingung untuk menggunakan nilai lag pada adf.test. Untuk membuat data menjadi stasioner akan dibahas lebih lanjut nanti Differencing Data bila tidak Stasioner
ref:
test captcha