

RNN (Recurrent Neural Network) dan MLP (Multi-Layer Perceptron) adalah dua jenis jaringan saraf yang berbeda. RNN memiliki mekanisme untuk mengingat konteks sebelumnya saat memproses input saat ini, yang membuatnya cocok untuk menangani data yang memiliki keterkaitan dalam waktu seperti teks, suara, atau video. Sedangkan MLP tidak memiliki mekanisme tersebut, sehingga lebih cocok untuk menangani data yang tidak memiliki keterkaitan dalam waktu. RNN juga memiliki lapisan hidden yang dapat diulang-ulang, sementara MLP hanya memiliki satu lapisan hidden. RNN lebih kompleks dari MLP dan memerlukan data latih yang cukup besar untuk mencapai kinerja yang baik.
RNN dapat digambarkan sebagai jaringan saraf yang memiliki lapisan hidden yang dapat diulang-ulang. Pada setiap iterasi, jaringan saraf ini akan menerima input dan menggunakan hidden state yang diingat dari iterasi sebelumnya untuk memproses input saat ini. Oleh karena itu, RNN dapat mengingat konteks sebelumnya dan menggunakannya untuk memahami konteks saat ini.
Salah satu keunggulan RNN adalah kemampuannya untuk menangani data yang sangat panjang. Karena RNN memiliki hidden state yang dapat mengingat konteks sebelumnya, jaringan saraf ini dapat menangani data yang sangat panjang tanpa harus mengabaikan informasi penting dari awal data.
RNN juga digunakan dalam berbagai aplikasi seperti natural language processing (NLP), generative models, dan pemrosesan suara. Dalam NLP, RNN digunakan untuk memahami konteks dari kalimat atau paragraf. Dalam generative models, RNN digunakan untuk menghasilkan teks atau suara yang sesuai dengan konteks yang diberikan. Dalam pemrosesan suara, RNN digunakan untuk mengidentifikasi suara yang berbeda dalam rekaman suara.
Meskipun RNN memiliki banyak keunggulan, jaringan saraf ini juga memiliki beberapa kelemahan. Salah satu kelemahan utama RNN adalah kesulitan dalam menangani data yang sangat panjang. Karena RNN mengingat konteks sebelumnya, jaringan saraf ini akan mengalami masalah ketika data yang diberikan sangat panjang dan konteks sebelumnya tidak lagi relevan.
Selain itu, RNN juga memerlukan data latih yang cukup besar untuk mencapai kinerja yang baik. Oleh karena itu, RNN tidak selalu cocok untuk aplikasi yang memerlukan data latih yang terbatas.
Perbedaan antara RNN dan MLP
Contents
Perbedaan utama antara keduanya adalah cara mereka menangani data yang memiliki keterkaitan dalam waktu.
- MLP tidak memiliki mekanisme untuk mengingat konteks sebelumnya saat memproses input saat ini. Ini membuat MLP lebih cocok untuk menangani data yang tidak memiliki keterkaitan dalam waktu.
- RNN memiliki hidden state yang memungkinkannya untuk mengingat konteks sebelumnya saat memproses input saat ini. Ini membuat RNN cocok untuk menangani data yang memiliki keterkaitan dalam waktu seperti teks, suara, atau video.
- MLP hanya memiliki satu lapisan hidden tetapi RNN memiliki lapisan hidden yang dapat diulang-ulang.
- MLP tidak dapat menangani data yang sangat panjang karena tidak memiliki mekanisme untuk mengingat konteks sebelumnya. Sedangkan RNN dapat menangani data yang sangat panjang karena memiliki hidden state yang dapat mengingat konteks sebelumnya.
- MLP lebih sederhana dari RNN, jadi lebih mudah untuk diimplementasikan dan diinterpretasikan, tetapi kurang fleksibel dalam menangani keterkaitan dalam waktu.
RNN (Recurrent Neural Network) adalah jenis jaringan saraf yang digunakan untuk memproses data yang memiliki keterkaitan dalam waktu. RNN menyimpan informasi tentang masa lalu melalui “hidden state” yang digunakan untuk memproses input saat ini. Ini memungkinkan RNN untuk mengenali pola dalam data yang berkaitan dengan waktu, seperti teks, suara, atau video. RNN juga dapat digunakan untuk generasi teks atau suara, karena jaringan dapat mengingat konteks sebelumnya saat menghasilkan output. Ada beberapa varian dari RNN, seperti LSTM (Long Short-Term Memory) dan GRU (Gated Recurrent Unit), yang dirancang untuk mengatasi masalah “vanishing gradient” yang terjadi pada RNN biasa.
Algoritma RNN
Algoritma RNN secara ringkas sebagai berikut
- Input data: Data yang akan diolah oleh RNN diterima sebagai input. Dalam beberapa kasus, data harus di-preprocessing terlebih dahulu sebelum diinput ke RNN.
- Encoding: Data yang diterima dikencode menjadi representasi vektor yang dapat diproses oleh jaringan.
- Forward propagation: Data vektor diinput ke jaringan dan diteruskan melalui lapisan-lapisan jaringan. Pada setiap waktu step, hidden state diperbarui dengan menggunakan informasi dari input saat ini dan hidden state sebelumnya.
- Output: Setelah data melewati seluruh lapisan jaringan, RNN menghasilkan output yang dapat digunakan untuk melakukan klasifikasi, penerjemahan, atau generasi teks.
- Decoding: Jika diperlukan, output RNN harus didecode kembali ke representasi asli data.
- Backpropagation: Melalui algoritma backpropagation, error dari output diteruskan kembali melalui jaringan untuk mengoptimalkan bobot jaringan dan meningkatkan kinerja RNN.
- Pemeliharaan: RNN dapat di-fine-tuning dengan data baru untuk meningkatkan kinerja dan menyesuaikan dengan perubahan dalam data.
Berikut beberapa keunggulan algoritma RNN yaitu
- Kemampuan untuk menangani data yang memiliki keterkaitan dalam waktu: RNN mampu menangani data yang memiliki keterkaitan dalam waktu seperti teks, suara, atau video. Ini membuat RNN cocok untuk aplikasi seperti penerjemahan otomatis, generasi teks, dan pengenalan suara.
- Kemampuan mengingat konteks sebelumnya: RNN memiliki hidden state yang memungkinkannya untuk mengingat konteks sebelumnya saat memproses input saat ini. Ini membuat RNN mampu mengenali pola dalam data yang berkaitan dengan waktu.
- Variasi yang tersedia: Ada beberapa varian dari RNN, seperti LSTM dan GRU, yang dapat digunakan untuk mengatasi masalah “vanishing gradient” yang terjadi pada RNN biasa.
- Kemampuan untuk generasi teks: RNN dapat digunakan untuk generasi teks karena jaringan dapat mengingat konteks sebelumnya saat menghasilkan output.
- Kemampuan untuk pemeliharaan: RNN dapat dine-tuning dengan data baru untuk meningkatkan kinerja dan menyesuaikan dengan perubahan dalam data.
- Kemampuan untuk menangani data yang tidak linear: RNN mampu menangani data yang tidak linear yang mengandung pola yang berbeda-beda dan tidak dapat ditentukan dari satu waktu saja.
Dengan beberapa keunggulan diatas, ternyata RNN juga beberapa kekurangan yaitu
- Vanishing Gradient Problem: RNN dapat mengalami masalah “vanishing gradient” ketika mencoba untuk mempelajari pola dalam data yang jauh dari input saat ini. Ini dapat menyebabkan jaringan kurang efektif dalam mempelajari pola yang terkait dengan waktu jauh.
- Exploding Gradient Problem: RNN juga dapat mengalami masalah “exploding gradient” ketika gradien yang digunakan dalam proses backpropagation terlalu besar dan menyebabkan bobot jaringan menjadi tidak stabil.
- Kemampuan untuk menangani data yang sangat panjang: RNN dapat mengalami kesulitan dalam menangani data yang sangat panjang karena hidden state hanya dapat mengingat informasi dari waktu sebelumnya yang terbatas.
- Memerlukan data latih yang cukup besar: RNN memerlukan data latih yang cukup besar untuk mencapai kinerja yang baik, terutama pada aplikasi yang kompleks.
- Kemampuan untuk menangani data yang berubah-ubah: RNN dapat mengalami kesulitan dalam menangani data yang berubah-ubah dan tidak stabil.
- Memerlukan komputasi yang cukup besar: RNN memerlukan komputasi yang cukup besar untuk melakukan forward dan backward propagation.
Jenis RNN
Untuk Jenis RNN ada banyak, yang nanti kita akan gunakan yaitu many to one yang artinya menerima banyak input untuk satu ouput saja, misalkan pada kasus NLP yang menerima banyak kata dalam 1 kalimat yang berbeda-beda panjang nya.
- One to One: Tipe RNN ini biasa digunakan untuk memecahkan masalah dalam machine learning. One to one juga dikenal sebagai vanilla neural network yang hanya bisa menampung satu input dan menghasilkan satu output saja.
- One to Many: Tipe berikutnya dari RNN yang dapat menghasilkan beberapa output atas satu input. Tipe ini banyak diaplikasikan pada caption gambar.
- Many to One: Ketiga adalah jenis many to one yang dapat menerima banyak input untuk menghasilkan satu output saja. Jenis ini paling sering digunakan untuk menentukan sentimen yang dapat mengklasifikasikan berdasarkan emosi negatif, netral, atau positif.
- Many to Many: Tipe terakhir yang dapat menerima banyak input dengan beberapa opsi output yang ditentukan berdasarkan urutan. Jenis ini banyak digunakan dalam mesin penerjemahan.
Persamaan umum dari algoritma RNN adalah sebagai berikut:
Berikut persamaan umum dari algoritma RNN
![\[ h_t = f(W_{xh} * x_t + W_{hh} * h_{t-1} + b_h) \]](https://softscients.com/wp-content/ql-cache/quicklatex.com-86f3a839a8b9b71d609b57c1ab7ae6d7_l3.png "Rendered by QuickLaTeX.com")
![\[ y_t = g(W_{hy} * h_t + b_y) \]](https://softscients.com/wp-content/ql-cache/quicklatex.com-20c8a95ba27405b3f40be9448f2ed1e6_l3.png "Rendered by QuickLaTeX.com")
di mana:
 adalah hidden state pada iterasi saat ini
adalah hidden state pada iterasi saat ini adalah input pada iterasi saat ini
adalah input pada iterasi saat ini adalah hidden state pada iterasi sebelumnya
adalah hidden state pada iterasi sebelumnya , dan
, dan  adalah matriks bobot yang digunakan untuk memproses input dan hidden state
adalah matriks bobot yang digunakan untuk memproses input dan hidden state dan
dan  adalah bias yang digunakan untuk memproses input dan hidden state
adalah bias yang digunakan untuk memproses input dan hidden state dan
dan  adalah fungsi aktivasi yang digunakan untuk memproses input dan hidden state
adalah fungsi aktivasi yang digunakan untuk memproses input dan hidden state
Dalam persamaan ini, fungsi digunakan untuk menghitung hidden state baru pada iterasi saat ini dengan menggabungkan input , hidden state dan bobot yang sesuai. Kemudian, fungsi digunakan untuk menghitung output  pada iterasi saat ini dengan menggunakan hidden state dan bobot yang sesuai.
pada iterasi saat ini dengan menggunakan hidden state dan bobot yang sesuai.
Secara umum, persamaan ini digunakan untuk mengolah input yang memiliki keterkaitan dalam waktu dengan mengingat konteks sebelumnya. Persamaan ini dapat diulang-ulang untuk memproses input yang panjang dan memungkinkan RNN untuk memahami konteks yang lebih luas.
Contoh Kasus Sederhana RNN
Contoh kasus sederhana RNN akan mempermudah kalian memahami istilah hidden state yang akan membedakannya dengan MLP. Berikut adalah variabel x yang mempunyai beberapa panjang array berbeda-beda, namun isinya mempunyai mode yang sama yaitu setiap 1 record mempunyai kombinasi angka genap atau ganjil saja.
x1 = np.array([0,2,4,6,8,0,2,2,2,2,2,6,8,]) x2 = np.array([1,3,1,5,7,9,7]) x3 = np.array([5,3,1,7,3]) x4 = np.array([7,3,9,1,9,9,9,9,9,7]) x5 = np.array([8,6,4,2,4,4,2,0,8]) x6 = np.array([8,4,0,0,0,0,0,2])
Tentu target nya seperti gampang ditebak yaitu 0 : genap dan 1 : ganjil
y1 = np.array([1.0]) y2 = np.array([0.0]) y3 = np.array([0.0]) y4 = np.array([0.0]) y5 = np.array([1.0]) y6 = np.array([1.0])
Data diatas mempunyai informasi sebagai berikut
- num_letters yaitu 0 sampai 9 atau mempunyai 10 item
- num_targets yaitu 0 dan 1 atau mempunyai 2 item
Sekilas sih emang sederhana, pakai logika if else saja sudah cukup untuk mengkategorikan record tersebut berupa genap atau ganjil, namun ini hanya untuk mempermudah saja dalam memahami cara kerja RNN.
Encoding One Hot Encoding
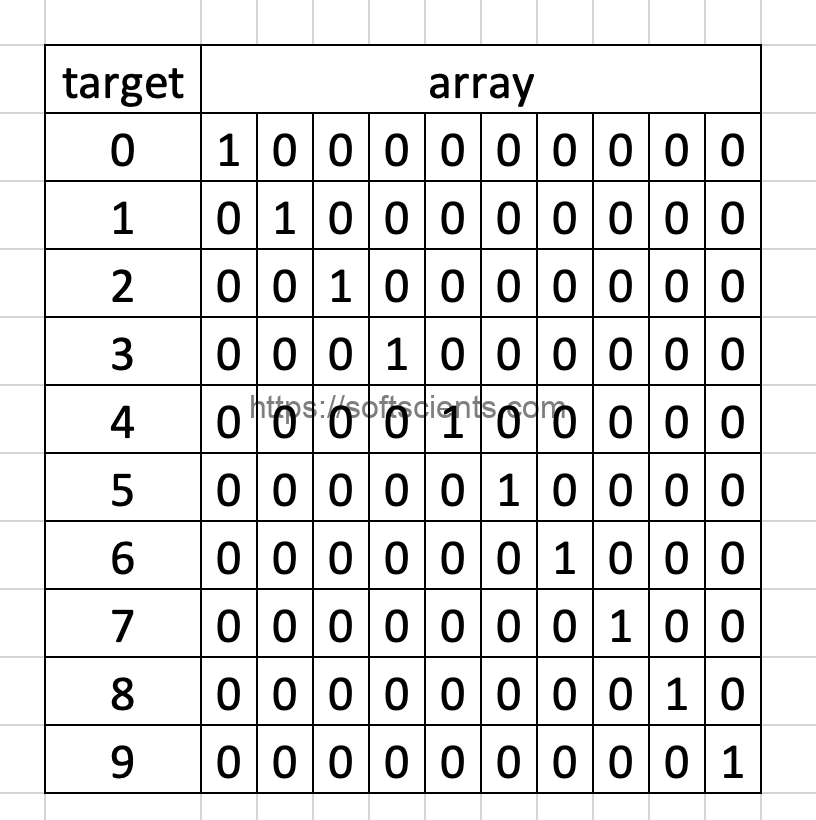
Yup.. yup kalian butuh yang namanya Encoding dengan teknik one hot encoding, Yuk Belajar membuat desain neural network dengan Tensorflow dan Pengenalan Angka Tulisan Tangan. Caranya cukup mudah kok, misalkan angka 5 akan di encode menjadi array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.]]) jadi setiap index pada vector one hot encoding akan diberikan nilai 1. Berarti kalau angka 9, maka array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]]) lebih jelasnya seperti berikut untuk one hot encoding (nanti buat function tersendiri dengan nama biner())
Misalnya nih kita punya record yang terdiri dari 3 anggota x1 = np.array([2,6,2]) maka akan ada 3 kali perulangan untuk 1 record. Setiap 1 perulangan akan disimpan hidden_state nya. Itulah mengapa ukuran setiap record bisa berbeda-beda panjang nya antara yang satu dengan yang lainnya.
Biar mudah, kita import dulu package yang dibutuhkan, sekalian kita buat variabel nya dengan memanfaatkan list untuk menampung record yang berbeda-beda.
import torch import torch.nn as nn import numpy as np x1 = np.array([0,2,4,6,8,0,2,2,2,2,2,6,8,]) x2 = np.array([1,3,1,5,7,9,7]) x3 = np.array([5,3,1,7,3]) x4 = np.array([7,3,9,1,9,9,9,9,9,7]) x5 = np.array([8,6,4,2,4,4,2,0,8]) x6 = np.array([8,4,0,0,0,0,0,2]) x = list() x.append(x1) x.append(x2) x.append(x3) x.append(x4) x.append(x5) x.append(x6) y1 = np.array([1.0]) y2 = np.array([0.0]) y3 = np.array([0.0]) y4 = np.array([0.0]) y5 = np.array([1.0]) y6 = np.array([1.0]) y = list() y.append(y1) y.append(y2) y.append(y3) y.append(y4) y.append(y5) y.append(y6)
Jangan lupa kita buat function untuk mengubah angka menjadi one hot encoding
def biner(index):
buffer = np.zeros([1,10])
buffer[0][index]=1.0
return buffer
Yuk kita buat model RNN sederhana, silahkan untuk login terlebih dahulu agar bisa melihat source code secara lengkap dibawah ini.
Sebagai catatan, kita akan membuat model RNN sendiri yang bukan bawaan dari Pytorch (nn.RNN) karena mencari RNN yang many to one versi pytorch belum nemu-nemu, sehingga kita buat saja agar makin paham cara kerjanya
num_letters = 10
num_targets = 2
hidden_size = 15
#buat model dulu
model = RNN(num_letters, hidden_size, num_targets)
x1 = np.array([2,6,2])
#hidden_state random
hidden_state = model.init_hidden()
#lakukan perulangan 1 record yang terdiri dari beberapa anggota
for j in range(0,len(x1)):
#jadikan one hot encoding
vector = biner(x1[j])
#ubah jadi tensor
inputs = torch.tensor(vector,dtype=torch.float)
#lakukan perhitungan forward
output, hidden_state = model(inputs, hidden_state)
_, pred = torch.max(output, dim=1)
print(pred)
Kalian bisa perhatikan hidden_state diawal dibuat secara random, kemudian dimasukan looping sebagai input untuk tahap selanjutnya.
Epoch 2000 kali
Yuk kita coba langsung saja untuk semua record
model = RNN(num_letters, hidden_size, num_targets)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(0,2000):
for i in range(0,len(x)):
record = x[i]
label = torch.tensor(y[i],dtype=torch.int64)
hidden_state = model.init_hidden()
for j in range(0,len(record)):
vector = biner(record[j])
inputs = torch.tensor(vector,dtype=torch.float)
output, hidden_state = model(inputs, hidden_state)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()
_, pred = torch.max(output, dim=1)
print("epoch : ",epoch,"record :",i," target: ",label," pred: ",pred," loss: ",loss.item())
Setelah di run akan menghasilkan loss semakin kecil
epoch : 998 record : 0 target: tensor([1]) pred: tensor([1]) loss: 0.0006841464783065021 epoch : 998 record : 1 target: tensor([0]) pred: tensor([0]) loss: 0.0003407612966839224 epoch : 998 record : 2 target: tensor([0]) pred: tensor([0]) loss: 0.0006280356901697814 epoch : 998 record : 3 target: tensor([0]) pred: tensor([0]) loss: 0.0003399271226953715 epoch : 998 record : 4 target: tensor([1]) pred: tensor([1]) loss: 0.0006027788622304797 epoch : 998 record : 5 target: tensor([1]) pred: tensor([1]) loss: 0.000841025379486382 epoch : 999 record : 0 target: tensor([1]) pred: tensor([1]) loss: 0.0006820021662861109 epoch : 999 record : 1 target: tensor([0]) pred: tensor([0]) loss: 0.00033968876232393086 epoch : 999 record : 2 target: tensor([0]) pred: tensor([0]) loss: 0.0006336349761113524 epoch : 999 record : 3 target: tensor([0]) pred: tensor([0]) loss: 0.00033885458833537996 epoch : 999 record : 4 target: tensor([1]) pred: tensor([1]) loss: 0.0006008726777508855 epoch : 999 record : 5 target: tensor([1]) pred: tensor([1]) loss: 0.0008384049870073795
Predict
Gimana mau melakukan predict? yuk kita buat sepert ini
def predict(record):
model.eval()
with torch.no_grad():
hidden_state = model.init_hidden()
for j in range(0,len(record)):
vector = biner(record[j])
##lakukan perhitungan
inputs = torch.tensor(vector,dtype=torch.float)
output, hidden_state = model(inputs, hidden_state)
_, pred = torch.max(output, dim=1)
model.train()
return pred
x1 = np.array([8,8,8,8,4,2,8])
print(predict(x1))
hasilnya record diatas adalah genap
tensor([1])
Hal menariknya adalah jika kita dengan sengaja memasukan angka genap dan ganjil dalam record, maka hasilnya adalah vooting alias yang banyak muncul apakah bilangan genap atau ganjil, seperti contoh berikut 8 angka genap dan 4 angka ganjil
x1 = np.array([4,2,0,1,3,1,7,9,8,8,6,2,6]) print(predict(x1))
Sehingga hasilnya genap alias 1
tensor([1])
Hal ini menandakan RNN mampu bekerja secara luwes sesuai prinsip kerjanya bisa menerima beragam panjang data, (tapi ada hal yang menarik lainnya, jika kita hanya isi 1 angka saja maka hasilnya bisa berbeda-beda, ya wajar saja karena init_hidden() menggunakan bilangan random, oleh sebab itu minimal terdiri dari 3 angka dalam 1 record)
Contoh RNN untuk klasifikasi judul berita
Salah satu kegunaan RNN yaitu untuk melakukan klasifikasi judul berita – Pytorch Studi Kasus Penerapan NLP pada Judul Berita. Cara kerjanya mirip yaitu dengan membuat one hot encoding, namun konsep nya seperti Membuat Document Term Matrix melalui penyusunan corpus terlebih dahulu. Alangkah baiknya sih langkah yang dilakukan seperti Cleaning Text Bahasa Indonesia dengan mengubah setiap kata menjadi kata dasarnya sehingga tercipta corpus yang bersih.
Referensi:
https://algorit.ma/blog/rnn-adalah-2022/
https://indoml.com/2018/04/04/pengenalan-rnn-bag-1/
https://skillplus.web.id/pengenalan-recurrent-neural-network-rnn/