
Seringnya kita akan menjumpai beragam ketidaksempurnaan, begitupun dalam hal dataset yang tidak sempurna dikarenakan keterbatasan waktu dan biaya. Hal tersebutlah yang akan menimbulkan inbalance dataset. Dataset yang tidak seimbang atau disebut juga sebagai “inbalanced dataset” merujuk pada situasi di mana distribusi kelas dalam dataset tidak merata. Dalam konteks klasifikasi, ini berarti ada perbedaan signifikan dalam jumlah sampel antara kelas yang berbeda. Dua kelas yang umumnya ada dalam suatu dataset adalah kelas mayoritas (majority class) dan kelas minoritas (minority class).
Sebagai contoh, pertimbangkan suatu dataset yang digunakan untuk mengenali apakah sebuah transaksi keuangan adalah penipuan atau bukan. Jika hanya sejumlah kecil transaksi yang merupakan penipuan, sedangkan sebagian besar transaksi adalah bukan penipuan, maka dataset tersebut dianggap tidak seimbang.
Dampak dari dataset yang tidak seimbang dapat menciptakan tantangan dalam proses pembelajaran mesin, terutama pada model klasifikasi. Beberapa dampak umum dari ketidakseimbangan dataset meliputi:
- Kinerja Menurun: Model yang dilatih pada dataset tidak seimbang mungkin cenderung memberikan prediksi yang bias ke arah kelas mayoritas, mengabaikan kelas minoritas. Oleh karena itu, akurasi model mungkin terlihat tinggi, tetapi sebenarnya, kemampuannya untuk mengidentifikasi kelas minoritas mungkin rendah.
- Bias Model: Model dapat mengembangkan bias terhadap kelas mayoritas, karena kurangnya representasi dari kelas minoritas dalam dataset. Sebagai hasilnya, model mungkin tidak dapat mengenali atau memahami dengan baik pola dalam kelas minoritas.
- Evaluasi yang Tidak Akurat: Metrik evaluasi seperti akurasi (accuracy) mungkin tidak mencerminkan kinerja sebenarnya dari model, terutama dalam kasus dataset tidak seimbang. Oleh karena itu, perlu mempertimbangkan metrik evaluasi alternatif seperti precision, recall, F1-score, atau area di bawah kurva ROC (AUC-ROC) yang lebih relevan untuk kasus-kasus ini.
Beberapa strategi untuk mengatasi dataset yang tidak seimbang termasuk:
- Resampling: Menggunakan teknik oversampling pada kelas minoritas atau undersampling pada kelas mayoritas untuk mencapai distribusi kelas yang lebih seimbang.
- Weighted Loss: Menyusun skema bobot pada fungsi kerugian sehingga model memberikan lebih banyak perhatian pada kelas minoritas.
- Metode Ensemble: Menggabungkan hasil dari beberapa model untuk meningkatkan kinerja, terutama dengan menggabungkan model yang dioptimalkan untuk kelas mayoritas dan kelas minoritas.
- Generasi Data Sintetis: Menciptakan data sintetis untuk kelas minoritas menggunakan teknik seperti SMOTE (Synthetic Minority Over-sampling Technique).
Pemilihan strategi tergantung pada karakteristik dataset dan tujuan spesifik dari masalah klasifikasi yang dihadapi.
Teknik Resampling untuk Inbalance Dataset
Contents
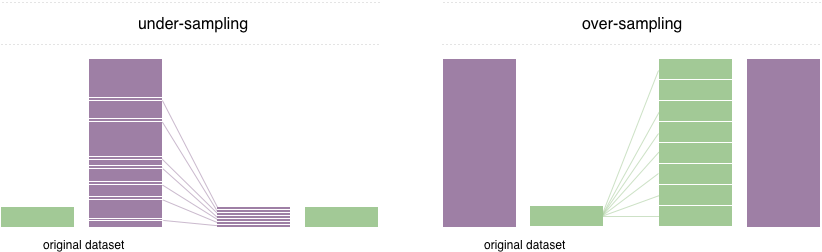
Dalam teknik resampling, kita bisa melihat ilustrasi berikut

sehingga akan disusun menjadi berikut
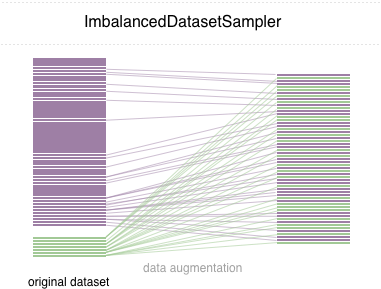
kalian bisa menggunakan https://github.com/ufoym/imbalanced-dataset-sampler dan ini bekerja secara smooth di pytorch
Marikicob – mari kita coba yuk, perbedaan berikut ini
data dummy inbalance
Kalian bisa melihat distribusi kelas untuk masing-masing data diatas dalam bentuk histogram
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
train_list = pd.read_excel('dummy.xlsx')
balance = train_list.groupby(['y']).count().reset_index()
fig, ax = plt.subplots()
data_X = balance['y']
data_Y = np.arange(len(data_X))
performance = balance['x']
error = np.random.rand(len(data_X))
ax.barh(data_Y, performance, xerr=error, align='center')
ax.set_yticks(data_Y)
ax.set_yticklabels(data_X)
ax.invert_yaxis() # labels read top-to-bottom
ax.set_xlabel('jumlah')
ax.set_title('sebaran data')
plt.show()

Mari kita coba buat loader dataset in pytorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
class DatasetKu(Dataset):
def __init__(self,dataset,transform = None):
self.dataset = dataset
self.labels = self.dataset['y']
def __len__(self):
return len(self.dataset)
def __getitem__(self,index):
images = self.dataset.loc[index,'x']
targets = self.dataset.loc[index,'y']
return images,targets
def get_labels(self):
return self.labels
kita loader tanpa shuffle biar nampak
dataset_train = DatasetKu(train_list)
batch_size = 4
train_dl = DataLoader(dataset_train,batch_size = batch_size,shuffle= False)
for batch in train_dl:
x,y = batch
print(y)
Kalian bisa lihat! di load secara urutan
tensor([0, 0, 0, 0]) tensor([0, 0, 0, 1]) tensor([1, 1, 1, 2]) tensor([2, 2, 3, 3]) tensor([3, 3, 4, 4])
Mari kita coba teknik inbalance sampler,
from torchsampler import ImbalancedDatasetSampler
train_dl2 = DataLoader(dataset_train,
sampler=ImbalancedDatasetSampler(dataset_train),
batch_size=batch_size)
for batch in train_dl2:
x,y = batch
print(y)
kalian akan terkejut, bahwa penyusunan nya mengikuti
- kelas 0 yang merupakan mayoritas akan mengalami under sampling
- kelas 4 akan yang merupakan minoritas akan mengalami over sampling
tensor([1, 0, 3, 3]) tensor([2, 1, 1, 3]) tensor([0, 0, 4, 3]) tensor([0, 2, 2, 4]) tensor([2, 4, 1, 1])
kelas 0 yang jumlah semula 7 akan menyusut hanya menjadi 4 (under sampling)
sedangkan kelas 4 yang jumlah semula 2 akan menjadi 3 (over sampling)
dan terlihat penyusunannya berimbang! sangat menarik dan setelah saya coba2 untuk dataset MNIST akan naik 1-2% akurasi nya dengan teknik diatas!
library imbalanced SMOTE Synthetic Minority Oversampling Technique
Selain menggunakan cara diatas, kalian juga bisa menggunakan library berikut https://imbalanced-learn.org/stable/auto_examples/combine/plot_comparison_combine.html#sphx-glr-auto-examples-combine-plot-comparison-combine-py
Namun ketika saya coba, masih saja terjadi error ketika import library nya
from imblearn.over_sampling import SMOTE
dengan pesan error sebagai berikut dengan scikit-learn 1.3.0
Traceback (most recent call last):
Cell In[1], line 1
from imblearn.over_sampling import SMOTE
File ~/anaconda3/lib/python3.11/site-packages/imblearn/__init__.py:52
from . import (
File ~/anaconda3/lib/python3.11/site-packages/imblearn/combine/__init__.py:5
from ._smote_enn import SMOTEENN
File ~/anaconda3/lib/python3.11/site-packages/imblearn/combine/_smote_enn.py:12
from ..base import BaseSampler
File ~/anaconda3/lib/python3.11/site-packages/imblearn/base.py:21
from .utils._param_validation import validate_parameter_constraints
File ~/anaconda3/lib/python3.11/site-packages/imblearn/utils/_param_validation.py:908
from sklearn.utils._param_validation import (
ImportError: cannot import name '_MissingValues' from 'sklearn.utils._param_validation' (/Users/mulkansyarif/anaconda3/lib/python3.11/site-packages/sklearn/utils/_param_validation.py)
solusinya yaitu downgrading to scikit-learn 1.2.2 fixed it for me
Mari coba menggunakan 2 class seperti berikut
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
X, y = make_classification(
n_samples=100,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.2, 0.7],
class_sep=0.8,
random_state=0,
)
# transform the dataset
oversample = SMOTE()
X2, y2 = oversample.fit_resample(X, y)
from matplotlib import pyplot as plt
plt.figure()
plt.subplot(1,2,1),plt.scatter(X[y==0][:,0],X[y==0][:,1])
plt.subplot(1,2,1),plt.scatter(X[y==1][:,0],X[y==1][:,1])
plt.subplot(1,2,1),plt.title("Sebelum")
plt.subplot(1,2,2),plt.scatter(X2[y2==0][:,0],X2[y2==0][:,1])
plt.subplot(1,2,2),plt.scatter(X2[y2==1][:,0],X2[y2==1][:,1])
plt.subplot(1,2,2),plt.title("Sesudah")
plt.show()
hasilnya

ref:
https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
SMOTE untuk multiclass
Mari kita coba, apakah SMOTE bisa untuk multiclass! menggunakan dataset berikut
import pandas as pd
from pandas import read_csv
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv'
df = read_csv(url, header=None, names=['a','b','c','d','e','f','g','h','i','j'])
sebaran = df.groupby('j')['j'].count()
print("sebaran\n",sebaran)
terlihat bahwa tiap-tiap kelas tidak mempunyai sebaran data yang rata!
sebaran j 1 70 2 76 3 17 5 13 6 9 7 29
kelas 1 punya 70 record, sedangkan kelas 6 hanya 9 record saja, mari kita plotkan dalam versi 3 dimensi
X = df.values[:,0:3] #ambil 3 fitur saja untuk mempermudah visualisasi
y = df.values[:,-1] # kelas nya
kelas = [1,2,3,5,6,7] # kelasnya itu tidak urut!
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
for k in kelas:
ax.scatter(X[y==k,0],X[y==k,1],X[y==k,2])
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
ax.set_title("Sebelum")
plt.show()

saya akan menggunakan strategy berikut ini
from imblearn.over_sampling import SMOTE
strategy = {1:100, 2:100, 3:200, 5:200, 6:200,7:100}
oversample = SMOTE(sampling_strategy=strategy)
X2, y2 = oversample.fit_resample(X, y)
maka nilai sebarannya akan menjadi berikut
sebaran2 = pd.DataFrame(y2,columns=['y']).groupby(['y'])['y'].count()
print("Sebaran \n",sebaran2)
hasil
y 1.0 100 2.0 100 3.0 200 5.0 200 6.0 200 7.0 100
Kita plotkan sebaran datanya
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
for k in kelas:
ax.scatter(X2[y2==k,0],X2[y2==k,1],X2[y2==k,2])
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
