
Google pertama kali memperkenalkan model transformer pada tahun 2017. Pada saat itu, model bahasa utamanya menggunakan jaringan saraf rekuren (RNN) dan jaringan saraf konvolusional (CNN) untuk menangani tugas pemrosesan bahasa alami (NLP).
CNN dan RNN merupakan model yang kompeten, namun, mereka memerlukan urutan data yang tetap untuk diproses. Model transformer dianggap sebagai perbaikan yang signifikan karena tidak memerlukan urutan data yang tetap untuk diproses.
Karena transformer dapat memproses data dalam urutan apa pun, mereka memungkinkan pelatihan pada jumlah data yang lebih besar daripada sebelumnya. Hal ini memfasilitasi pembuatan model yang telah dilatih sebelumnya seperti BERT, yang dilatih pada jumlah data bahasa yang besar sebelum dirilis.
Pada tahun 2018, Google memperkenalkan dan mengopen-source-kan BERT. Dalam tahap penelitian, kerangka kerja ini mencapai hasil terkini dalam 11 tugas pemahaman bahasa alami (NLU), termasuk analisis sentimen, labeling peran semantik, klasifikasi teks, dan disambiguasi kata dengan banyak makna. Peneliti di Google AI Language menerbitkan laporan pada tahun yang sama yang menjelaskan hasil-hasil ini.
Menyelesaikan tugas-tugas ini membedakan BERT dari model bahasa sebelumnya, seperti word2vec dan GloVe. Model-model tersebut terbatas dalam menginterpretasikan konteks dan kata-kata polisemik, atau kata-kata dengan banyak makna. BERT secara efektif mengatasi ambiguitas, yang merupakan tantangan terbesar bagi NLU, menurut peneliti di bidang tersebut. BERT mampu memparsing bahasa dengan nalar umum yang relatif mirip manusia.
Pada bulan Oktober 2019, Google mengumumkan bahwa mereka akan mulai menerapkan BERT pada algoritma pencarian produksi berbasis AS mereka.
Diperkirakan bahwa BERT meningkatkan pemahaman Google terhadap sekitar 10% dari kueri pencarian bahasa Inggris berbasis AS. Google merekomendasikan agar organisasi tidak mencoba mengoptimalkan konten untuk BERT, karena BERT bertujuan untuk memberikan pengalaman pencarian yang alami. Pengguna disarankan untuk menjaga kueri dan konten yang difokuskan pada subjek yang alami dan pengalaman pengguna yang alami.
Pada bulan Desember 2019, BERT telah diterapkan pada lebih dari 70 bahasa yang berbeda. Model ini telah memiliki dampak besar pada pencarian suara serta pencarian berbasis teks, yang sebelum tahun 2018 sering kali bermasalah dengan teknik NLP Google. Setelah BERT diterapkan pada banyak bahasa, itu meningkatkan optimisasi mesin pencari; keahliannya dalam memahami konteks membantu dalam menginterpretasikan pola-pola yang berbeda yang dibagikan oleh berbagai bahasa tanpa harus benar-benar memahami bahasa tersebut.
BERT kemudian mempengaruhi banyak sistem kecerdasan buatan. Berbagai versi ringan dari BERT dan metode pelatihan serupa telah diterapkan pada model dari GPT-2 hingga ChatGPT.
Bagaimana BERT Bekerja
Contents
Tujuan dari teknik pemrosesan bahasa alami (NLP) apa pun adalah untuk memahami bahasa manusia sebagaimana diucapkan secara alami. Dalam kasus BERT, ini berarti memprediksi sebuah kata dalam suatu teks yang kosong. Untuk melakukannya, model-model tersebut biasanya dilatih menggunakan repositori besar data pelatihan yang bersifat khusus dan berlabel. Proses ini melibatkan ahli linguistik dalam melakukan pelabelan data secara manual yang melelahkan.
Namun, BERT dilatih sebelumnya menggunakan hanya koleksi teks polos tanpa label, yaitu seluruh Wikipedia dalam bahasa Inggris dan Korpus Brown. BERT terus belajar melalui pembelajaran tanpa pengawasan dari teks tanpa label dan meningkat bahkan ketika digunakan dalam aplikasi praktis seperti pencarian Google.
Pra-pelatihan BERT berfungsi sebagai lapisan pengetahuan dasar dari mana ia dapat membangun responsnya. Dari sana, BERT dapat beradaptasi dengan konten dan kueri yang dapat dicari yang terus berkembang, dan dapat disesuaikan dengan spesifikasi pengguna. Proses ini dikenal sebagai pembelajaran transfer. Selain dari proses pra-pelatihan ini, BERT memiliki beberapa aspek lain yang bergantung padanya untuk berfungsi sebagaimana yang diharapkan, termasuk yang berikut:
Transformer
Karya Google pada transformer membuat BERT menjadi mungkin. Transformer adalah bagian dari model yang memberikan BERT kapasitas yang meningkat untuk memahami konteks dan ambiguitas dalam bahasa. Transformer memproses kata yang diberikan dalam hubungannya dengan semua kata lain dalam sebuah kalimat, daripada memprosesnya satu per satu. Dengan melihat semua kata di sekitarnya, transformer memungkinkan BERT untuk memahami konteks lengkap dari kata tersebut dan dengan demikian lebih memahami niat pencari.
Hal ini berbeda dengan metode tradisional pemrosesan bahasa, yang dikenal sebagai penyemat kata. Pendekatan ini digunakan dalam model seperti GloVe dan word2vec. Ini akan memetakan setiap kata ke dalam vektor, yang mewakili hanya satu dimensi dari makna kata tersebut.
masked-language modeling (MLM) – Pemodelan Bahasa Tersembunyi
Model penyemat kata memerlukan kumpulan data besar dari data terstruktur. Meskipun mereka pandai dalam banyak tugas NLP umum, mereka gagal dalam sifat prediktif yang membutuhkan konteks yang kaya, seperti jawaban atas pertanyaan, karena semua kata dalam beberapa cara terhubung ke dalam vektor atau makna tertentu.
BERT menggunakan metode MLM untuk menghalangi kata yang difokuskan dari melihat dirinya sendiri, atau memiliki makna tetap yang independen dari konteksnya. BERT dipaksa untuk mengidentifikasi kata yang di-masker berdasarkan konteks saja. Dalam BERT, kata-kata didefinisikan oleh lingkungannya, bukan oleh identitas yang telah ditetapkan sebelumnya.
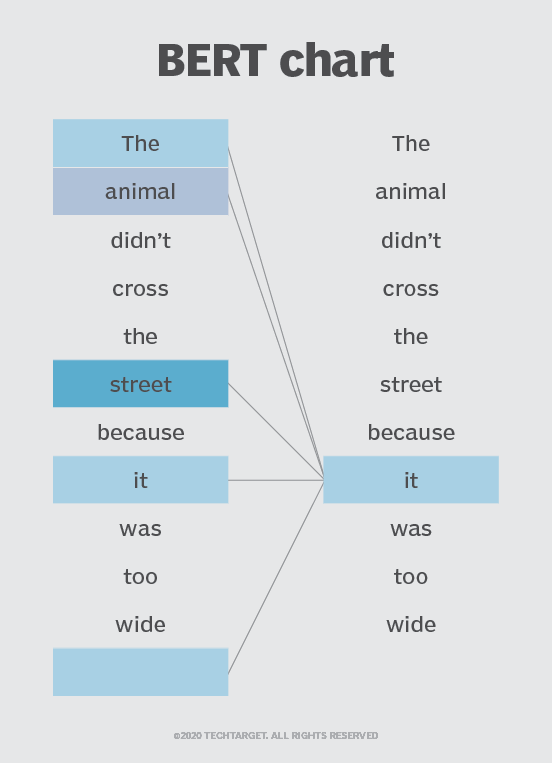
Mekanisme Perhatian Diri BERT juga bergantung pada mekanisme perhatian diri yang menangkap dan memahami hubungan antara kata-kata dalam sebuah kalimat. Transformer berarah ganda yang menjadi inti desain BERT membuat hal ini menjadi mungkin. Ini penting karena seringkali, sebuah kata dapat mengubah maknanya seiring dengan perkembangan sebuah kalimat. Setiap kata yang ditambahkan memperkuat makna keseluruhan kata yang menjadi fokus algoritma NLP. Semakin banyak kata yang hadir dalam setiap kalimat atau frasa, semakin ambigu kata yang menjadi fokusnya. BERT memperhitungkan penambahan makna tersebut dengan membaca secara berarah ganda, memperhitungkan pengaruh semua kata lain dalam sebuah kalimat terhadap kata fokus dan mengeliminasi momentum dari kiri ke kanan yang memihak kata-kata ke arah makna tertentu seiring perkembangan sebuah kalimat.
Sebagai contoh, dalam gambar di atas, BERT menentukan kata sebelumnya dalam kalimat yang dimaksudkan oleh kata “it”, dan kemudian menggunakan mekanisme perhatian diri untuk menimbang pilihan-pilihan tersebut. Kata dengan skor terhitung tertinggi dianggap sebagai asosiasi yang benar. Dalam contoh ini, “it” merujuk kepada “animal”, bukan “street”. Jika frasa ini adalah kueri pencarian, hasilnya akan mencerminkan pemahaman yang lebih halus dan lebih tepat yang dicapai oleh BERT
Next sentence prediction – Prediksi Kalimat Berikutnya
Prediksi Kalimat Berikutnya NSP adalah teknik pelatihan yang mengajarkan BERT untuk memprediksi apakah suatu kalimat tertentu mengikuti kalimat sebelumnya untuk menguji pengetahuannya tentang hubungan antara kalimat-kalimat. Secara khusus, BERT diberikan pasangan kalimat yang dipasangkan dengan benar dan pasangan yang dipasangkan secara salah sehingga ia menjadi lebih baik dalam memahami perbedaannya. Seiring waktu, BERT menjadi lebih baik dalam memprediksi kalimat berikutnya secara akurat. Umumnya, baik teknik NSP maupun MLM digunakan secara bersamaan.
Apa yang digunakan BERT untuk?
Google menggunakan BERT untuk mengoptimalkan interpretasi dari kueri pencarian pengguna. BERT sangat baik dalam fungsi-fungsi yang membuat ini menjadi mungkin, termasuk yang berikut:
Tugas-tugas pembangkitan bahasa urutan-ke-urutan seperti:
- Jawaban pertanyaan.
- Ringkasan abstrak.
- Prediksi kalimat berikutnya.
- Pembangkitan respon percakapan. Tugas-tugas NLU seperti:
- Resolusi polisemi dan koreferensi. Koreferensi berarti kata-kata yang terdengar atau terlihat sama tetapi memiliki makna yang berbeda.
- Disambiguasi makna kata.
- Inferensi bahasa alami.
- Klasifikasi sentimen. BERT adalah open source, artinya siapa pun dapat menggunakannya. Google mengklaim bahwa pengguna dapat melatih sistem tanya-jawab terkini dalam waktu hanya 30 menit menggunakan unit pemrosesan tensor cloud, dan dalam beberapa jam menggunakan unit pemrosesan grafis. Banyak organisasi lain, kelompok penelitian, dan faksi terpisah dari Google sedang menyempurnakan arsitektur model dengan pelatihan terawasi untuk mengoptimalkannya untuk efisiensi atau mengkhususkannya untuk tugas-tugas tertentu dengan memprediksi kembali BERT dengan representasi kontekstual tertentu. Contoh-contoh termasuk yang berikut:
- PatentBERT. Model BERT ini disesuaikan untuk melakukan tugas klasifikasi paten.
- DocBERT. Model ini disesuaikan untuk tugas klasifikasi dokumen.
- BioBERT. Model representasi bahasa biomedis ini adalah untuk penambangan teks biomedis.
- VideoBERT. Model visual-linguistik bersama ini digunakan dalam pembelajaran tidak terawasi dari data tanpa label di YouTube.
- SciBERT. Model ini adalah untuk teks ilmiah.
- G-BERT. Model BERT pra-dilatih ini menggunakan kode medis dengan representasi hierarkis melalui jaringan neural grafik dan kemudian disesuaikan untuk membuat rekomendasi medis.
- TinyBERT oleh Huawei. BERT “murah” yang lebih kecil ini belajar dari BERT “guru” asli, melakukan distilasi transformer untuk meningkatkan efisiensi. TinyBERT menghasilkan hasil yang menjanjikan dibandingkan dengan BERT-base sambil menjadi 7,5 kali lebih kecil dan 9,4 kali lebih cepat dalam inferensi.
- DistilBERT oleh Hugging Face. Versi BERT yang lebih kecil, lebih cepat, dan lebih murah ini dilatih dari BERT, kemudian beberapa aspek arsitektur dihapus untuk meningkatkan efisiensi.
- ALBERT. Versi yang lebih ringan dari BERT ini mengurangi konsumsi memori dan meningkatkan kecepatan dengan cara model dilatih.
- SpanBERT. Model ini meningkatkan kemampuan BERT untuk memprediksi jangkauan teks.
- RoBERTa. Melalui metode pelatihan yang lebih canggih, model ini dilatih pada kumpulan data yang lebih besar untuk waktu yang lebih lama untuk meningkatkan kinerja.
- ELECTRA. Versi ini telah disesuaikan untuk menghasilkan representasi teks berkualitas tinggi
ref: