

Sinopsis
Contents
Algoritma Clustering yang paling sering dibahas dan digunakan yaitu K-Mean Clustering, namum algoritma tersebut kurang robust jika menghadapi dataset yang bersifat non linear karena hanya mengandalkan jarak ke titik centroid tanpa ada atribut yang lainnya. Hal ini berbeda dengan Algoritma Fuzzy C-Means Clustering yang mempunyai atribut jarak juga mempunyai nilai keanggotannya sehingga sangat diandalkan dan cocok jika ditemui dataset yang bersifat non linear seperti dibawah ini.
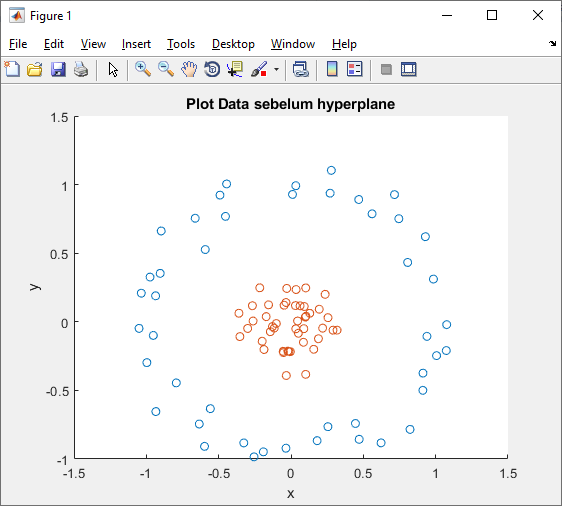
Hal yang akan sulit dilakukan oleh K-Means Clustering. Sekedar kalian tahu selain 2 algoritma tersebut ada banyak sekali algoritma clustering yaitu
- k-means clustering algorithm
- Fuzzy c-means clustering algorithm
- Hierarchical clustering algorithm
- Gaussian(EM) clustering algorithm
- Quality threshold clustering algorithm
- MST based clustering algorithm
- kernel k-means clustering algorithm
- Density-based clustering algorithm
Penerapan Algoritma Clustering
Algoritma clustering sangat membantu pekerjaan manusia dalam banyak hal terutama untuk menganalisis perilaku data seperti
- Recommender systems
- Anomaly detection
- Human genetic clustering
- Genom Sequence analysis
- Analysis of antimicrobial activity
- Grouping of shopping items
- Search result grouping
- Slippy map optimization
- Crime analysis
- Climatology
Contoh Dataset
Ok setelah kalian membaca sinopsisnya yang lumayan singkat diatas. Kalian akan diajak untuk penerapan Fuzzy C-Means Clustering untuk Iris Data (http://www.softscients.web.id/2017/12/matlab-classification-learner-example.html) yang terdiri dari 4 atribut input dan 3 kelas target dengan jumlah data sebanyak 150 record. Gambaran umum mengenai Iris Data yaitu (https://en.wikipedia.org/wiki/Iris_setosa) Iris Setosa dengan detail berikut.

Dengan paramater nya yaitu petal dan sepal yang terdiri dari panjang dan lebarnya. https://en.wikipedia.org/wiki/Petal

Bila sudah memahami data yang akan kita olah. Kalian tidak perlu download datanya karena Matlab sudah menyediakan data yang kita butuhkan, cukup kita panggil dengan function berikut
clc;clear all;close all; load iris.dat
Terdiri dari 5 kolom yaitu

Seperti berikut

Dimana kode iris / target kelas (pada kolom ke 5)
- setosa
- versicolor
- virginica
Visualisasi Data
Setelah paham, kita akan visualisasikan dalam bentuk 2 Dimensi yaitu sumbu X dan sumbu Y, kita akan menggunakan 2 paramater yaitu

clc;clear all;close all;
load iris.dat
x = [iris(:,1), iris(:,end)];
y = [iris(:,3),iris(:,end)];
setosa_x = x(x(:,end)==1);
setosa_y = y(y(:,end)==1);
versicolor_x = x(x(:,end)==2);
versicolor_y = y(y(:,end)==2);
virginica_x = x(x(:,end)==3);
virginica_y = y(y(:,end)==3);
figure,
scatter(setosa_x,setosa_y,'fill'); %setosa
hold on
scatter(versicolor_x,versicolor_y,'fill'); %versicolor
scatter(virginica_x,virginica_y,'fill'); %virginica
legend('setosa','versicolor','virginica')
xlabel('sepal length');
ylabel('petal length');
title('Visualisasi Data Iris');
menghasilkan

Clustering
Kita akan mencari Center masing-masing paramater menggunakan Fuzzy C-Means Clustering, silahkan untuk mempelajari code matlab berikut yaitu menggunakan function  yang sudah tersedia di Matlab
yang sudah tersedia di Matlab
fcm Data set clustering using fuzzy c-means clustering.
[CENTER, U, OBJ_FCN] = fcm(DATA, N_CLUSTER) finds N_CLUSTER number of
clusters in the data set DATA. DATA is size M-by-N, where M is the number of
data points and N is the number of coordinates for each data point. The
coordinates for each cluster center are returned in the rows of the matrix
CENTER. The membership function matrix U contains the grade of membership of
each DATA point in each cluster. The values 0 and 1 indicate no membership
and full membership respectively. Grades between 0 and 1 indicate that the
data point has partial membership in a cluster. At each iteration, an
objective function is minimized to find the best location for the clusters
and its values are returned in OBJ_FCN.
[CENTER, ...] = fcm(DATA,N_CLUSTER,OPTIONS) specifies a vector of options
for the clustering process:
OPTIONS(1): exponent for the matrix U (default: 2.0)
OPTIONS(2): maximum number of iterations (default: 100)
OPTIONS(3): minimum amount of improvement (default: 1e-5)
OPTIONS(4): info display during iteration (default: 1)
The clustering process stops when the maximum number of iterations
is reached, or when the objective function improvement between two
consecutive iterations is less than the minimum amount of improvement
specified. Use NaN to select the default value.
Kalian bisa terapkan pada Data Iris
clc;clear all;close all;
load iris.dat
x = [iris(:,1), iris(:,end)];
y = [iris(:,3),iris(:,end)];
setosa_x = x(x(:,end)==1);
setosa_y = y(y(:,end)==1);
versicolor_x = x(x(:,end)==2);
versicolor_y = y(y(:,end)==2);
virginica_x = x(x(:,end)==3);
virginica_y = y(y(:,end)==3);
figure,
scatter(setosa_x,setosa_y,'fill'); %setosa
hold on
scatter(versicolor_x,versicolor_y,'fill'); %versicolor
scatter(virginica_x,virginica_y,'fill'); %virginica
legend('setosa','versicolor','virginica')
xlabel('sepal length');
ylabel('petal length');
title('Visualisasi Data Iris');
cluster_n = 3; % Number of clusters
expo = 2.0; % Exponent for U
max_iter = 100; % Max. iteration
min_impro = 1e-6; % Min. improvement
min_display = 5;
opsi = [expo max_iter min_impro min_display];
data = [x(:,1),y(:,1)];
[U, center, obj] = fcm(data,cluster_n,opsi);
for i=1:size(U,1)
text(U(i,1),U(i,2),num2str(i),'FontWeight', 'bold','FontSize',20);
end
Jika run berkali-kali, akan menghasilkan berbeda-beda.

Karena kita menggunakan bilangan random sehingga nilainya berpindah-pindah, tapi itu bukan fokus kita, yang menjadi fokus kita adalah kita sudah menemukan center untuk ketiga jenis iris

Titik Center sebagai penentu jenis iris
Lalu bagaimana cara menggunakan nya? Bila sudah ditemukan center? Misalkan kita menggunakan sample no 3 (seharusnya termasuk iris setosa), mari kita cek
sample = data(3,:); %misalkan kita ambil data no 3
jarak = [];
for i =1:3
jarak(i) = norm(U(i,:) - sample);
end
[value,indeks] = sort(jarak);
indeks_terkecil = indeks(1);
if indeks_terkecil == 1
disp('Jenis Versicolor')
elseif indeks_terkecil ==2
disp('Jenis Setosa')
elseif indeks_terkecil==3
disp('Jenis Virginica');
end
hasil
Jenis Setosa
Sangat mudah sekali bukan? penggunakan dengan memanfaatkan function pada Matlab.