

Pada topik ini kita akan membahas mengenai Natural Languange Processing (NLP) yang saat ini telah mengalami pertumbuhan yang cepat terutama karena kinerja kemampuan model bahasa untuk secara akurat “memahami” bahasa manusia lebih cepat saat menggunakan pelatihan tanpa pengawasan pada korpora teks besar. Misalnya, pembuatan kalimat menggunakan GPT-3 atau model teks yang telah dilatih sebelumnya seperti BERT menyederhanakan banyak tugas NLP, dan secara dramatis meningkatkan kinerja.
Kita akan fokus pada aspek-aspek mendasar dari representasi NLP sebagai tensor di PyTorch, dan pada arsitektur NLP klasik seperti penggunaan bag-of-words (BoW), penyisipan kata, jaringan saraf berulang, dan jaringan generatif.
Natural Languange Processing digunakan untuk
Contents
Ada beberapa tugas NLP yang secara tradisional kami coba selesaikan menggunakan jaringan saraf:
- Klasifikasi Teks digunakan ketika kita perlu mengklasifikasikan fragmen teks ke dalam salah satu dari beberapa kelas yang telah ditentukan sebelumnya. Contohnya termasuk deteksi spam email, kategorisasi berita, menetapkan permintaan dukungan ke salah satu kategori, dan banyak lagi.
- Intent Classification adalah salah satu kasus spesifik dari klasifikasi teks, ketika kita ingin memetakan ucapan input dalam sistem AI percakapan menjadi salah satu maksud yang mewakili makna sebenarnya dari frasa, atau maksud pengguna.
- Analisis Sentimen adalah tugas regresi, di mana kita ingin memahami tingkat negatif dari bagian teks yang diberikan. Kita mungkin ingin memberi label teks dalam kumpulan data dari yang paling negatif (-1) hingga yang paling positif (+1), dan melatih model yang akan menampilkan sejumlah “kepositifan” dari sebuah teks.
- Named Entity Recognition (NER) adalah tugas mengekstrak beberapa entitas dari teks, seperti tanggal, alamat, nama orang, dll. Bersama dengan klasifikasi maksud, NER sering digunakan dalam sistem dialog untuk mengekstrak parameter dari ucapan pengguna.
Tugas serupa ekstraksi kata kunci dapat digunakan untuk menemukan kata-kata yang paling bermakna di dalam teks, yang kemudian dapat digunakan sebagai tag. - Peringkasan Teks mengekstrak potongan teks yang paling bermakna, memberi pengguna versi terkompresi yang berisi sebagian besar makna.
- Question/Answer – Pertanyaan/Jawaban adalah tugas mengekstraksi jawaban dari sepotong teks. Model ini mendapatkan fragmen teks dan pertanyaan sebagai input, dan perlu menemukan tempat yang tepat di dalam teks yang berisi jawaban. Misalnya, teks “John adalah siswa berusia 22 tahun yang suka menggunakan Microsoft Learn”, dan pertanyaan Berapa umur John harus memberikan jawaban kepada kita 22.
Contoh Kasus Natural Languange Processing
Untuk ruang lingkup modul ini, sebagian besar kita akan fokus pada tugas klasifikasi teks. Kita akan menggunakan teks dari tajuk berita untuk mengklasifikasikan salah satu dari 4 kategori yang termasuk dalam kategori ini: Dunia, Olahraga, Bisnis, dan Sains/Teknologi. Kita juga akan memperkenalkan model generatif yang dapat menghasilkan sendiri urutan teks seperti manusia.
Syarat
Sebagai syarat penting untuk mulai tentang Natural Languange Processing, kalian sudah mengerti dasar-dasar Python, machine learning, deep learning, pytorch. Silahkan bagi kalian yang belum mengerti agar bisa belajar di website ini
1. Mengubah teks menjadi Tensor/Angka
Yup sebuah mesin/robot hanya mengerti angka, itupun bilangan biner! Seperti pada bab computer vision yang menggunakan array 3 layer sebagai input kepada komputer, maka begitu juga dengan teks yang harus diubah terlebih dahulu ke dalam angka/tensor. Hem.. bagaimana caranya??
Jika kita ingin menyelesaikan tugas Natural Language Processing (NLP) dengan jaringan saraf, kita memerlukan beberapa cara untuk merepresentasikan teks sebagai tensor. Komputer sudah mewakili karakter tekstual sebagai angka yang dipetakan ke font di layar komputer. menggunakan pengkodean seperti ASCII atau UTF-8. Gambar yang menunjukkan diagram yang memetakan karakter ke ASCII dan representasi biner

Perhatikan bahwa setiap huruf dan bagaimana semua karakter berkumpul untuk membentuk kata-kata dalam sebuah kalimat. Namun, komputer sendiri tidak memiliki pemahaman seperti itu, dan jaringan saraf harus mempelajari artinya selama pelatihan.
Oleh karena itu, kita dapat menggunakan pendekatan yang berbeda saat merepresentasikan teks:
- Representasi tingkat karakter, ketika kita merepresentasikan teks dengan memperlakukan setiap karakter sebagai angka. Mengingat bahwa kita memiliki C karakter yang berbeda dalam korpus teks, kata Halo akan diwakili oleh 5 × C tensor. Setiap huruf akan sesuai dengan kolom tensor dalam penyandian one-hot
- Representasi tingkat kata, saat kita membuat kosa kata dari semua kata dalam urutan teks atau kalimat kita, dan kemudian mewakili setiap kata menggunakan penyandian satu arah. Pendekatan ini entah bagaimana lebih baik, karena setiap huruf dengan sendirinya tidak memiliki banyak arti, dan dengan demikian dengan menggunakan konsep semantik tingkat tinggi akan menyederhanakan tugas untuk jaringan saraf. Namun, mengingat ukuran kamus yang besar, kita perlu berurusan dengan tensor sparse berdimensi tinggi. Misalnya, jika kita memiliki ukuran kosakata 10.000 kata yang berbeda. Kemudian setiap kata akan memiliki panjang pengkodean one-hode sebanyak 10.000; karenanya berdimensi tinggi.
Untuk menyatukan pendekatan tersebut, kita biasanya menyebut potongan teks atom sebagai token. Dalam beberapa kasus, token dapat berupa huruf, dalam kasus lain – kata, atau bagian dari kata. Misalkan kata ibu tidak punya arti apapun / kata benda, akan tetapi kalimat ibu menyapu akan mempunyai arti berkegiatan.
Proses mengubah teks menjadi rangkaian token disebut tokenization. Selanjutnya, kita perlu menetapkan setiap token ke nomor, yang dapat kita masukkan ke dalam jaringan saraf. Ini disebut vektorisasi, dan biasanya dilakukan dengan membangun kosakata token. Pernah saya bahas dibawah ini
Cara menghitung term frequency dan inverse document frequency
Yuk kita install dulu, syarat yang digunakan
!pip install -r https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/nlp-pytorch/requirements.txt
Atau kalian bisa memilih beberapa package yang belum terinstall (saya sedikit ubah version torchtext=0.5.0)
gensim==3.8.3 huggingface==0.0.1 matplotlib==3.3.2 nltk==3.5 numpy==1.22.2 opencv-python==4.5.5.62 Pillow==9.0.1 scikit-learn==0.23.2 scipy==1.4.1 torch==1.12.0 torchaudio==0.8.1 torchinfo==0.0.8 torchtext==0.13.0 torchvision==0.9.1 transformers==4.3.3
2. Klasifikasi Teks
Dalam modul ini, kita akan mulai dengan tugas klasifikasi teks sederhana berdasarkan dataset sampel AG_NEWS, yaitu mengklasifikasikan berita utama ke dalam salah satu dari 4 kategori: Dunia, Olahraga, Bisnis, dan Sains/Teknologi. Dataset ini dibuat dari modul torchtext PyTorch, sehingga kita dapat mengaksesnya dengan mudah.
import torch from torchtext.datasets import AG_NEWS #download dataset train_iter = AG_NEWS(split='train')
Kita akan memanggil datase tersebut sebanyak 5 record
kategori = ['World', 'Sports', 'Business', 'Sci/Tech'] #misalkan saja, kita akan cari tahu record pertama for idx,(kelas,tajuk) in enumerate (train_iter): print(idx,kategori[kelas],tajuk,"\n") if(idx==4): break
hasilnya ada 5 tajuk berita yang dikategorikan sebagai sci/tech
0 Sci/Tech Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again. 1 Sci/Tech Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group,\which has a reputation for making well-timed and occasionally\controversial plays in the defense industry, has quietly placed\its bets on another part of the market. 2 Sci/Tech Oil and Economy Cloud Stocks' Outlook (Reuters) Reuters - Soaring crude prices plus worries\about the economy and the outlook for earnings are expected to\hang over the stock market next week during the depth of the\summer doldrums. 3 Sci/Tech Iraq Halts Oil Exports from Main Southern Pipeline (Reuters) Reuters - Authorities have halted oil export\flows from the main pipeline in southern Iraq after\intelligence showed a rebel militia could strike\infrastructure, an oil official said on Saturday. 4 Sci/Tech Oil prices soar to all-time record, posing new menace to US economy (AFP) AFP - Tearaway world oil prices, toppling records and straining wallets, present a new economic menace barely three months before the US presidential elections.
karena dataset tersebut masih berbentuk iterator, kita akan mengkonvert kedalam list agar dapat mengetahui jumlah record nya
#ukuran data n = len(list(enumerate(train_iter)))
Wow ukuran yang sangat besar untuk train_iter mempunyai 120 ribu record
3. Tokenisasi dan Vektorisasi
Belajar Natural Languange Processing NLP yaitu melakukan tokenisasi. Sekarang kita perlu mengonversi teks menjadi angka yang dapat direpresentasikan sebagai tensor untuk memasukkannya ke dalam jaringan saraf. Langkah pertama adalah mengonversi teks menjadi token – tokenization. Jika kita menggunakan representasi tingkat kata, setiap kata akan diwakili oleh tokennya sendiri. Kami akan menggunakan tokenizer bawaan dari modul torchtext.
Agar lebih, saya akan sajikan dalam contoh kecil saja dengan menggunakan beberapa kalimat berikut
kalimat = list()
kalimat.append("Apa perbedaan artikel dan tajuk rencana?")
kalimat.append("Apa yang dimaksud dengan tajuk rencana?")
kalimat.append("Siapa yang menulis tajuk rencana?")
kalimat.append("Apa yang dimaksud dengan opini tajuk rencana?")
Token akan memecah kalimat menjadi kata-perkata menggunakan package tokenizer
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
#digunakan untuk memecah kalimat menjadi kata-perkata
tokenizer = get_tokenizer('basic_english')
Kita coba saja untuk kalimat pertama
token = tokenizer(kalimat[0]) print(token)
hasilnya
['apa', 'perbedaan', 'artikel', 'dan', 'tajuk', 'rencana', '?']
Semua kalimat tersebut akan dibuat token selanjutnya token2 tersebut akan dibuat vocab/kumpulan kata.
def yield_tokens(data_iter):
for text in data_iter:
yield tokenizer(text)
#membuat database kata/vocab
vocab = build_vocab_from_iterator(yield_tokens(kalimat), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
for i in range(0,len(vocab)):
print(i,vocab.lookup_token(i))
Vocab inilah yang merupakan database token
0 <unk> 1 ? 2 rencana 3 tajuk 4 apa 5 yang 6 dengan 7 dimaksud 8 artikel 9 dan 10 menulis 11 opini 12 perbedaan 13 siapa
Kita ingin tahu kalimat pertama tersebut dalam sebuah vocab menempati index berapa saja?
#untuk mempermudah mencari index kata dalam vocab text_pipeline = lambda x: vocab(tokenizer(x)) #mencoba untuk kalimat pertama text_pipeline(kalimat[0])
hasilnya
[4, 12, 8, 9, 3, 2, 1]
artinya kata pada kalimat pertama yaitu [‘apa’, ‘perbedaan’, ‘artikel’, ‘dan’, ‘tajuk’, ‘rencana’, ‘?’] dijabarkan sebagai berikut
- apa menempati index 4
- perbedaan : index 12
- artikel: index 8
- dan : index 9
- tajuk: index 3
- rencana: index 2
- ?: index 1
Sekarang kita tambahkan juga untuk target/kelas
label_pipeline = lambda x: int(x) - 1 #class/target
4. Data Loader
Selanjutnya kita akan membuat data loader yang akan loading data per batch. Misalkan menggunakan 8 batch artinya 1 kali epoch akan menggunakan 8 record sekaligus. Offset digunakan sebagai solusi karena setiap kalimat tersebut mempunyai panjang/jumlah token/suku kata yang berbeda-beda.
Data loader juga bertugas untuk membuat class/target dan feature menjadi tensor
#membuat function untuk data loader per batch
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
#untuk menangani setiap panjang kalimat yang berbeda-beda
#maka digunakan sebuah offsets
#offset index 0 bernilai 0
label_list, text_list, offsets = [], [], [0]
for (_label, _text) in batch:
#kelas/target
label_list.append(label_pipeline(_label))
#feature dibuat tensor yang isinya index token dalam vocab
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
#dapatkan ukuran/size tiap tensor kalimat
offsets.append(processed_text.size(0))
#buat tensor kelas/target
label_list = torch.tensor(label_list, dtype=torch.int64)
#buat tensor offsets
#lakukan total kumulatif
#tapi index terakhir tidak ikut dijumlahkan!
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
#disusun/digabung
text_list = torch.cat(text_list)
return label_list.to(device), text_list.to(device), offsets.to(device)
Coba kita akan panggil function tersebut sebagai argument collate_fn function pada class DataLoader
dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch)
Yuk kita coba cari tahu isi dataloader
#coba kita cari tahu apa isi dataloader label,text,offsets = next(iter(dataloader)) print(label,offsets,text)
hasilnya, kalian bisa lihat ada 8 record yang mempunyai class = 2 / business. Ke 8 kalimat tersebut digabung menjadi 1 data record menggunakan perintah text_list = torch.cat(text_list)
Oiya saya tidak begitu paham menggunakan akumulasi dengan index terakhir yang tidak ikut digunakan offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
Mungkin pembaca disini ada tahu.
Berikut isi dari dataloader
tensor([2, 2, 2, 2, 2, 2, 2, 2])
tensor([ 0, 29, 71, 111, 151, 194, 242, 289])
tensor([ 431, 425, 1, 1605, 14838, 113, 66, 2, 848, 13,
27, 14, 27, 15, 50725, 3, 431, 374, 16, 9,
67507, 6, 52258, 3, 42, 4009, 783, 325, 1, 15874,
1072, 854, 1310, 4250, 13, 27, 14, 27, 15, 929,
797, 320, 15874, 98, 3, 27657, 28, 5, 4459, 11,
564, 52790, 8, 80617, 2125, 7, 2, 525, 241, 3,
28, 3890, 82814, 6574, 10, 206, 359, 6, 2, 126,
1, 58, 8, 347, 4582, 151, 16, 738, 13, 27,
14, 27, 15, 2384, 452, 92, 2059, 27360, 2, 347,
8, 2, 738, 11, 271, 42, 240, 51953, 38, 2,
294, 126, 112, 85, 220, 2, 7856, 6, 40066, 15380,
1, 70, 7376, 58, 1810, 29, 905, 537, 2846, 13,
27, 14, 27, 15, 838, 39, 4978, 58, 68871, 29,
2, 905, 2846, 7, 537, 70, 58874, 703, 5, 912,
2520, 93, 89171, 3, 30, 58, 293, 26, 10, 114,
1, 58, 92, 4379, 4, 3581, 145, 3, 7577, 23,
12282, 4, 36, 347, 13, 105, 14, 105, 15, 90056,
50, 58, 92, 3, 11312, 1732, 8, 13750, 9735, 3,
3593, 5, 23, 365, 12282, 3470, 94, 299, 167, 2,
36, 399, 545, 1, 151, 152, 43, 3, 45, 355,
71, 2280, 13, 27, 14, 27, 15, 151, 789, 1357,
280, 10, 70411, 4433, 355, 2280, 11, 2, 71, 19,
58, 92, 2301, 353, 468, 55934, 715, 3, 12933, 5,
1617, 738, 29, 179, 77320, 64, 1, 13, 846, 1,
371, 14, 756, 1207, 439, 7, 307, 85, 13, 31,
14, 31, 15, 1766, 6, 2, 407, 16, 9, 832,
756, 126, 2145, 1207, 439, 24, 468, 108, 1, 782,
139, 7, 2, 307, 85, 4, 468, 56748, 1, 8874,
6852, 3, 2, 797, 54, 3007, 26, 60, 1, 1355,
1236, 517, 13945, 38, 1416, 13, 2199, 1, 172, 14,
2199, 1, 172, 15, 832, 124, 5951, 113, 5, 2539,
7, 1232, 3, 8, 23, 571, 11, 2444, 1687, 439,
69, 85, 3, 2, 100, 26, 60, 3, 7126, 2,
347, 21, 2566, 29, 5, 26470, 3676, 1])
5. Membuat Arsitektur Deep Learning
Langkah selanjutnya yaitu membuat arsitektur deep learning dengan instance dari nn.Module,
#membuat arsitektur jaringan
from torch import nn
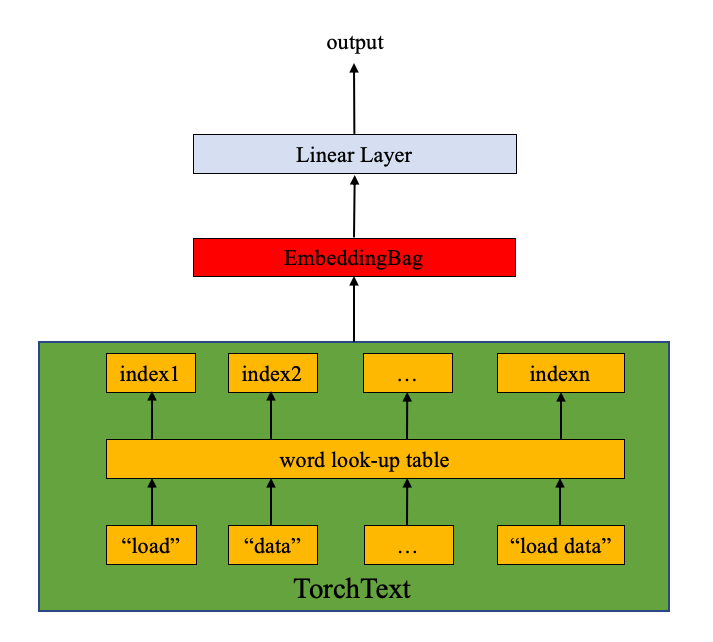
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
Sekarang kita buat model dari class diatas
num_class = len(set([label for (label, text) in train_iter])) vocab_size = len(vocab) emsize = 64 model = TextClassificationModel(vocab_size, emsize, num_class).to(device)
Kita lihat model nya sebagai berikut
TextClassificationModel( (embedding): EmbeddingBag(95811, 64, mode=mean) (fc): Linear(in_features=64, out_features=4, bias=True) )
Ada 95811 ciri fitur yang dimasukan dengan target sebanyak 4 kelas. 95811 Node tersebut menggunakan function linear menjadi 64 node
6. Training dan Evaluate
Langkah selanjutnya kita buat function training dan evaluate
# Hyperparameters
EPOCHS = 10 # epoch
LR = 5 # learning rate
BATCH_SIZE = 64 # batch size for training
import time
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
criterion = torch.nn.CrossEntropyLoss()
def train(dataloader,epoch):
model.train()
total_acc, total_count = 0, 0
log_interval = 500
start_time = time.time()
for idx, (label, text, offsets) in enumerate(dataloader):
optimizer.zero_grad()
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)
optimizer.step()
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches '
'| accuracy {:8.3f}'.format(epoch, idx, len(dataloader),
total_acc/total_count))
total_acc, total_count = 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (label, text, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc/total_count
7. Sesi pelatihan
Sekarang saatnya running
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
train_iter, test_iter = AG_NEWS()
train_dataset = to_map_style_dataset(train_iter)
test_dataset = to_map_style_dataset(test_iter)
num_train = int(len(train_dataset) * 0.95)
split_train_, split_valid_ = \
random_split(train_dataset, [num_train, len(train_dataset) - num_train])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader,epoch)
accu_val = evaluate(valid_dataloader)
if total_accu is not None and total_accu > accu_val:
scheduler.step()
else:
total_accu = accu_val
print('-' * 59)
print('| end of epoch {:3d} | time: {:5.2f}s | '
'valid accuracy {:8.3f} '.format(epoch,
time.time() - epoch_start_time,
accu_val))
print('-' * 59)
hasilnya adalah hanya dengan 10 iterasi didapatkan akurasi sebanyak 90.6%
| epoch 1 | 500/ 1782 batches | accuracy 0.683 | epoch 1 | 1000/ 1782 batches | accuracy 0.857 | epoch 1 | 1500/ 1782 batches | accuracy 0.877 ----------------------------------------------------------- | end of epoch 1 | time: 30.55s | valid accuracy 0.884 ----------------------------------------------------------- | epoch 2 | 500/ 1782 batches | accuracy 0.899 | epoch 2 | 1000/ 1782 batches | accuracy 0.902 | epoch 2 | 1500/ 1782 batches | accuracy 0.902 ----------------------------------------------------------- | end of epoch 2 | time: 26.16s | valid accuracy 0.891 ----------------------------------------------------------- | epoch 3 | 500/ 1782 batches | accuracy 0.913 | epoch 3 | 1000/ 1782 batches | accuracy 0.914 | epoch 3 | 1500/ 1782 batches | accuracy 0.916 ----------------------------------------------------------- | end of epoch 3 | time: 26.88s | valid accuracy 0.900 ----------------------------------------------------------- | epoch 4 | 500/ 1782 batches | accuracy 0.927 | epoch 4 | 1000/ 1782 batches | accuracy 0.924 | epoch 4 | 1500/ 1782 batches | accuracy 0.922 ----------------------------------------------------------- | end of epoch 4 | time: 28.28s | valid accuracy 0.892 ----------------------------------------------------------- | epoch 5 | 500/ 1782 batches | accuracy 0.935 | epoch 5 | 1000/ 1782 batches | accuracy 0.938 | epoch 5 | 1500/ 1782 batches | accuracy 0.937 ----------------------------------------------------------- | end of epoch 5 | time: 35.64s | valid accuracy 0.904 ----------------------------------------------------------- | epoch 6 | 500/ 1782 batches | accuracy 0.939 | epoch 6 | 1000/ 1782 batches | accuracy 0.939 | epoch 6 | 1500/ 1782 batches | accuracy 0.936 ----------------------------------------------------------- | end of epoch 6 | time: 35.25s | valid accuracy 0.906 ----------------------------------------------------------- | epoch 7 | 500/ 1782 batches | accuracy 0.939 | epoch 7 | 1000/ 1782 batches | accuracy 0.938 | epoch 7 | 1500/ 1782 batches | accuracy 0.940 ----------------------------------------------------------- | end of epoch 7 | time: 33.93s | valid accuracy 0.905 ----------------------------------------------------------- | epoch 8 | 500/ 1782 batches | accuracy 0.940 | epoch 8 | 1000/ 1782 batches | accuracy 0.939 | epoch 8 | 1500/ 1782 batches | accuracy 0.941 ----------------------------------------------------------- | end of epoch 8 | time: 30.18s | valid accuracy 0.906 ----------------------------------------------------------- | epoch 9 | 500/ 1782 batches | accuracy 0.940 | epoch 9 | 1000/ 1782 batches | accuracy 0.941 | epoch 9 | 1500/ 1782 batches | accuracy 0.941 ----------------------------------------------------------- | end of epoch 9 | time: 29.24s | valid accuracy 0.906 ----------------------------------------------------------- | epoch 10 | 500/ 1782 batches | accuracy 0.941 | epoch 10 | 1000/ 1782 batches | accuracy 0.942 | epoch 10 | 1500/ 1782 batches | accuracy 0.941 ----------------------------------------------------------- | end of epoch 10 | time: 27.87s | valid accuracy 0.906 -----------------------------------------------------------
mari kita evaluasi Natural Languange Processing untuk klasifikasi tajuk berita yaitu
#evaluate
print('Checking the results of test dataset.')
accu_test = evaluate(test_dataloader)
print('test accuracy {:8.3f}'.format(accu_test))
hasilnya
Checking the results of test dataset. test accuracy 0.907
cukup akurat 90.7%
Test dengan tajuk berita yang lain
ag_news_label = {1: "World",
2: "Sports",
3: "Business",
4: "Sci/Tec"}
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item() + 1
ex_text_str = "MEMPHIS, Tenn. – Four days ago, Jon Rahm was \
enduring the season’s worst weather conditions on Sunday at The \
Open on his way to a closing 75 at Royal Portrush, which \
considering the wind and the rain was a respectable showing. \
Thursday’s first round at the WGC-FedEx St. Jude Invitational \
was another story. With temperatures in the mid-80s and hardly any \
wind, the Spaniard was 13 strokes better in a flawless round. \
Thanks to his best putting performance on the PGA Tour, Rahm \
finished with an 8-under 62 for a three-stroke lead, which \
was even more impressive considering he’d never played the \
front nine at TPC Southwind."
model = model.to("cpu")
print("tajuk berita \n",ex_text_str,"\n termasuk \n")
print("This is a %s news" %ag_news_label[predict(ex_text_str, text_pipeline)])
hasilnya
tajuk berita MEMPHIS, Tenn. – Four days ago, Jon Rahm was enduring the season’s worst weather conditions on Sunday at The Open on his way to a closing 75 at Royal Portrush, which considering the wind and the rain was a respectable showing. Thursday’s first round at the WGC-FedEx St. Jude Invitational was another story. With temperatures in the mid-80s and hardly any wind, the Spaniard was 13 strokes better in a flawless round. Thanks to his best putting performance on the PGA Tour, Rahm finished with an 8-under 62 for a three-stroke lead, which was even more impressive considering he’d never played the front nine at TPC Southwind. termasuk This is a Sports news
Bagaimana menurut kalian pembahasan mengenai Natural Language Processing, nanti kita akan terapkan pada tajuk-tajuk berita dari kompas.com. Penerapan Natural Language Processing untuk Klasifikasi Judul Berita
ref:
https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html