
Sinopsis
Contents
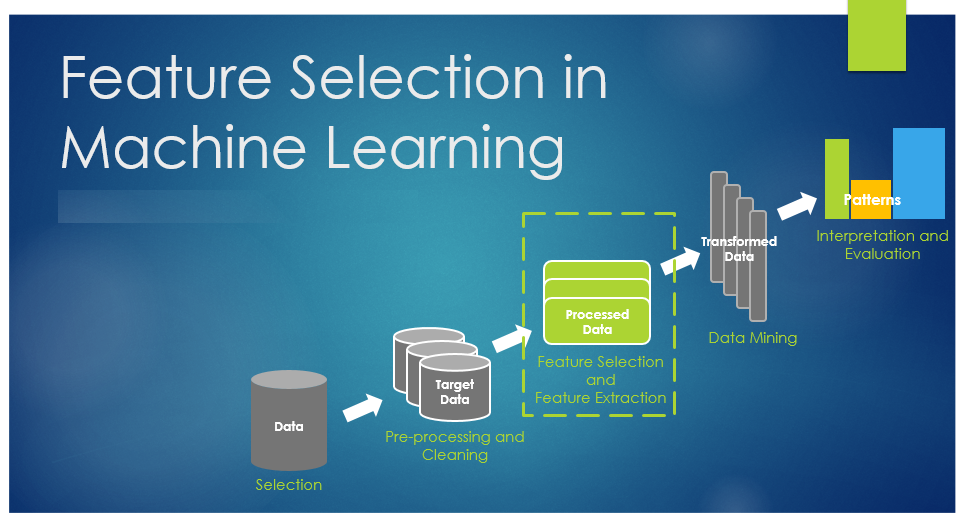
Berbicara analisis data, maka tahap paling penting yaitu feature selection yang berguna untuk ‘membuang’ data yang tidak ada korelasinya, sehingga akan meningkatkan keakuratan data dalam melakukan prediksi. Untuk contoh simplenya ada di link berikut http://www.softscients.web.id/2017/11/univariate-feature-selection-for.html

Bahwa paramater/feature volume tidak signifikan terhadap kelas/target dari group. Pada postingan kali ini, kita akan menggunakan analisis korelasi. Secara sederhana, korelasi dapat diartikan sebagai hubungan antara dua variabel yang bersifat kuantitatif. Lebih lanjut ke Ref: http://ciputrauceo.net/blog/2016/5/16/pengertian-korelasi-dan-macam-macam-korelasi. Untuk dataset yang digunakan yaitu https://www.kaggle.com/uciml/breast-cancer-wisconsin-data yaitu terdiri dari 31 feature untuk membedakan 2 kelas/target untuk Diagnosis jaringan payudara yaitu M (malignant) dan B (Benign). Kita akan memberikan 2 perlakuan yaitu tanpa ada seleksi fitur dan dengan seleksi fitur. Seperti biasa, kita akan menggunakan Python, pandas, dan Numpy, Sklearn, untuk melakukan hal tersebut, lebih lanjut ke http://www.softscients.web.id/2018/11/buku-belajar-mudah-python-dengan.html
#DATASET
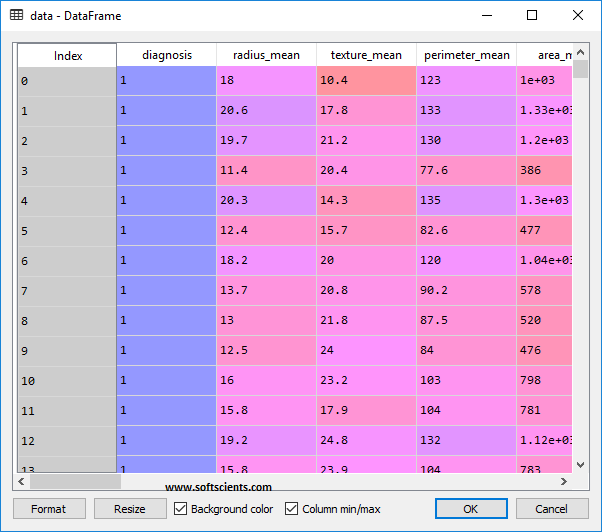
Dataset yang digunakan akan diload menggunakan pandas

Seperti biasa, dataset diatas disajikan menggunakan Pandas, kita akan mengubah beberapa hal yaitu
- Menghilangkan kolom id, karena tidak digunakan
- Mengubah kolom diagnosis dari M dan B menjadi 1 dan 0
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv('data.csv')
data = data.iloc[:,1:-1] #remove kolom id
label_encoder = LabelEncoder()
data.iloc[:,0] = label_encoder.fit_transform(data.iloc[:,0]).astype('float64') #mengubah value diagnosis menjadi 1 dan 0
Menyiapkan parameter dan target
paramater = data.iloc[:,1:-1] target = data.iloc[:,0]
Split dataset dengan 0.2 atau 20% sebagai data test, sisanya 80% sebagai data training.
x_train, x_test, y_train, y_test = train_test_split(paramater.values, target.values, test_size = 0.2)
#TANPA ADA SELEKSI FITUR
Untuk teknik clustering yaitu SVC support vector clustering http://www.scholarpedia.org/article/Support_vector_clustering; https://arxiv.org/abs/1804.10905
svc = SVC() # The default kernel adalah gaussian kernel
svc.fit(x_train, y_train)
prediction = svc.predict(x_test)
print("Akurasi:",metrics.accuracy_score(y_test, prediction))
menghasilkan
Akurasi: 0.6403508771929824
#DENGAN SELEKSI FITUR
Kita akan menghitung matrix correlation
#menghitung correlation corr_matrix = paramater.corr().abs()

Pahami bahwa data yang digunakan, adalah matrix segitiga atasnya
#ambil matrix segitiga atas upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
Temukan nama kolom dengan nilai diatas 0.9

Bila menggunakan excel sebagai berikut

Maka kolom dengan tanda merah, akan dihapus
#temukan feature dengan correlation diatas 0.9
to_drop = [column for column in upper.columns if any(upper[column] > 0.9)]
for ls in to_drop:
paramater=paramater.drop([ls],axis=1)
Berikut nama feature yang dibuang

Dengan clustering SVC seperti diatas
x_train, x_test, y_train, y_test = train_test_split(paramater.values, target.values, test_size = 0.2)
svc = SVC() # The default kernel adalah gaussian kernel
svc.fit(x_train, y_train)
prediction = svc.predict(x_test)
print("Akurasi:",metrics.accuracy_score(y_test, prediction))
Menghasilkan
Akurasi: 0.9473684210526315
Tingkat akurasi data jauh meningkat dari semula 0.64 menjadi 0.94
Kode Lengkap untuk Tanpa Seleksi Fitur
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
np.random.seed(123)
data = pd.read_csv('data.csv')
data = data.iloc[:,1:-1] #remove kolom id
label_encoder = LabelEncoder()
data.iloc[:,0] = label_encoder.fit_transform(data.iloc[:,0]).astype('float64') #mengubah value diagnosis menjadi 1 dan 0
paramater = data.iloc[:,1:-1]
target = data.iloc[:,0]
x_train, x_test, y_train, y_test = train_test_split(paramater.values, target.values, test_size = 0.2)
svc = SVC() # The default kernel adalah gaussian kernel
svc.fit(x_train, y_train)
prediction = svc.predict(x_test)
print("Akurasi:",metrics.accuracy_score(y_test, prediction))
Dengan Seleksi Fitur
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
np.random.seed(123)
data = pd.read_csv('data.csv')
data = data.iloc[:,1:-1] #remove kolom id
label_encoder = LabelEncoder()
data.iloc[:,0] = label_encoder.fit_transform(data.iloc[:,0]).astype('float64') #mengubah value diagnosis menjadi 1 dan 0
paramater = data.iloc[:,1:-1]
target = data.iloc[:,0]
#menghitung correlation
corr_matrix = paramater.corr().abs()
#ambil matrix segitiga atas
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
#temukan feature dengan correlation diatas 0.9
to_drop = [column for column in upper.columns if any(upper[column] > 0.9)]
for ls in to_drop:
paramater=paramater.drop([ls],axis=1)
x_train, x_test, y_train, y_test = train_test_split(paramater.values, target.values, test_size = 0.2)
svc = SVC() # The default kernel adalah gaussian kernel
svc.fit(x_train, y_train)
prediction = svc.predict(x_test)
print("Akurasi:",metrics.accuracy_score(y_test, prediction))