
Pytorch Mengenal Arsitektur LeNet untuk klasifikasi objek – Deep Learning adalah sebuah model jaringan syaraf tiruan yang sekarang ini mulai banyak digunakan dan dikembangkan pada computer vision dan didukung oleh murahnya harga teknologi Graphic Processing Unit (GPU) yang bekerja secara pararel. Salah satu contoh Deep Learning yang digunakan untuk pengenalan citra adalah Convolutional Neural Network (CNN).
Convolutional Neural Network (CNN) adalah pengembangan dari metode Multi Layer Perceptron (MLP). Metode CNN lebih baik daripada metode Multi Layer Perceptron (MLP) mengingat CNN mempunyai keunggulan kedalaman jaringan yang tinggi dan sering diaplikasikan pada data pengenalan citra sehingga mampu menghasilkan tingkat akurasi tinggi dan hasil yang baik.
Perbedaan dengan MLP yang hanya menganggap bahwa setiap piksel adalah fitur yang independen sehingga menghasilkan hasil yang kurang baik! padahal setiap nilai spasial atau nilai pixel tetangga mempunyai pengaruh dengan yang lain. Arsitektur pada Convolutional Neural Network (CNN) memiliki kemampuan untuk mengekstraksi fitur secara otomatis. Banyak macam arsitektur Convolutional Neural Network (CNN) yang populer untuk digunakan, contohnya LeNet-5 (1998), AlexNet (2012), ZFNet (2013), VGGNet (2014), GoogLeNet (2014), ResNet (2015), FractalNet (2016) dan arsitektur yang lainnya
LeNet
Saat ini versi LeNet sudah mencapai LeNet-5 adalah suatu jaringan yang memiliki lapisan banyak berbasis Convolutional Neural Network (CNN) pertama kali yang dikenalkan oleh Yann LeCun. LeNet 5 mempunyai jumlah lapisan yang lebih banyak daripada versi LeNet sebelumnya. Melihat referensi https://blog.ineuron.ai/Implementation-of-LeNet-Architecture-with-Pytorch-with-MNIST-Dataset-Fj8e9Sl22Z. Arsitektur LeNet dapat dijabarkan sebagai berikut
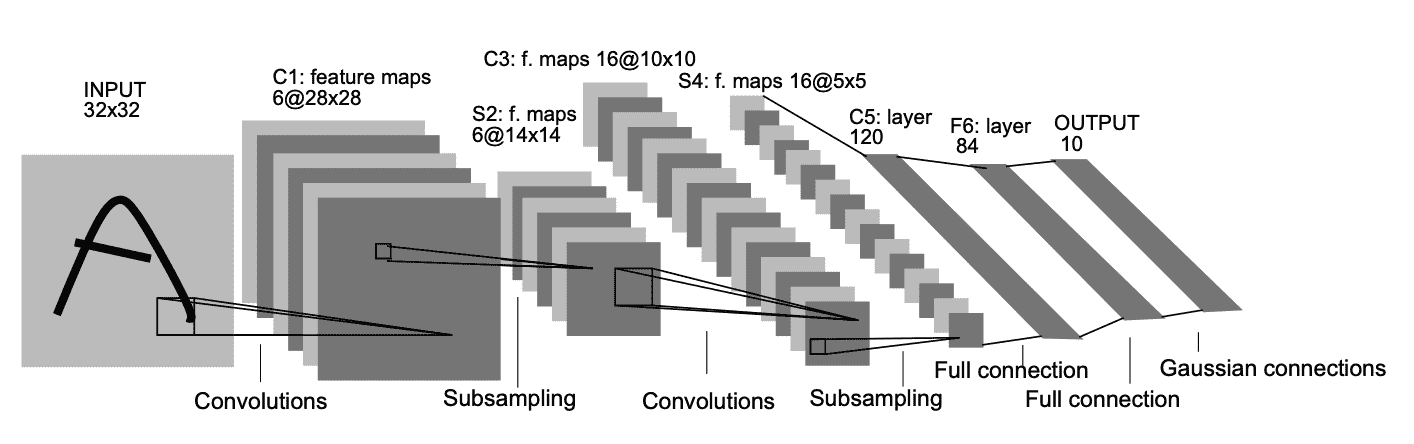
Penjabaran sebagai berikut
- Input untuk LeNet-5 adalah gambar skala abu-abu yang berukuran 32x32x1 melalui lapisan convolutional dengan 6 feature maps dengan ukuran filter 5×5 dan satu stride.
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(5,5),padding=0,stride=1)
- 6 feature maps ini adalah channel dari gambar yang sudah dilakukan operasi konvolusi dengan setiap ukuran 28x28x6. Stride digunakan untuk mengontrol seberapa besar pergeseran dari suatu filter pada layer saat melewati serangkaian data. Pada lapisan ini digunakan fungsi aktivasi tanh yang terdapat pada kernel size.
- Kemudian Lapisan kedua (S2) merupakan lapisan pooling layer dengan ukuran filter 2×2, 6 feature maps dan dua stride. Pada lapisan ini masih sama dengan lapisan sebelumnya menggunakan fungsi aktivasi tanh dengan dimensi gambar yang dihasilkan menjadi 14x14x6.
- Selanjutnya ada lapisan convolutional kedua dengan 16 feature maps yang memiliki ukuran filter 5×5 dengan fungsi aktivasi tanh dan satu stride dengan output didapakan dimensi gambar berukuran 10x10x16.
- Lapisan keempat (S4) merupakan pooling layer dengan jenis average pooling layer atau max pooling layer yang memiliki filter berukuran 2×2 dengan aktivasi tanh dan dua stride. Lapisan ini hampir sama dengan lapisan kedua (S2), hanya saja pada lapisan ini memiliki 16
feature maps. Pada lapisan ini terdapat 400 nodes yang akan dihubungkan dengan 5x5x16 dengan output didapatkan dimensi gambar 5x5x16. - Lapisan kelima (C5) merupakan fully connected layer dengan 120 feature maps pada masing – masing ukuran 1X1 dengan fungsi aktivasi tanh. Masing – masing dari 120 nodes di lapisan kelima terhubung ke semua 400 nodes yang ada di lapisan keempat (S4). 120 nodes ini
telah ditetapkan dari arsitektur LeNet-5. - Untuk lapisan keenam (F6) merupakan fully connected layer dengan nodes yang berjumlah sebanyak 84 nodes sehingga output didapatkan parameter latih sebanyak 10164 nodes.
- Pada lapisan terakhir atau output layer merupakan fully connected yang menggunakan fungsi aktivasi softmax dengan size 5 berdasarkan dengan hasil output gambar yang diklasifikasikan.
Arsitektur LeNet 5 yang ditulis dalam Pytorch sebagai berikut
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
#Here, we are plementing those layers which are having learnable parameters.
#Start implementation of Layer 1 (C1) which has 6 kernels of size 5x5 with padding 0 and stride 1
self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(5,5),padding=0,stride=1)
#Start implementation of Layer 3 (C3) which has 16 kernels of size 5x5 with padding 0 and stride 1
self.conv2 = nn.Conv2d(in_channels = 6, out_channels = 16,kernel_size = (5,5),padding=0,stride=1)
#Start implementation of Layer 5 (C5) which is basically flattening the data
self.conv3 = nn.Conv2d(in_channels = 16, out_channels = 120,kernel_size = (5,5),padding=0,stride=1)
#Start implementation of Layer 6 (F6) which has 85 Linear Neurons and input of 120
self.L1 = nn.Linear(120,84)
#Start implementation of Layer 7 (F7) which has 10 Linear Neurons and input of 84
self.L2 = nn.Linear(84,10)
#We have used pooling of size 2 and stride 2 in this architecture
self.pool = nn.AvgPool2d(kernel_size = 2, stride = 2)
#We have used tanh as an activation function in this architecture so we will use tanh at all layers excluding F7.
self.act = nn.Tanh()
#Now we will implement forward function to produce entire flow of the architecture.
def forward(self,x):
x = self.conv1(x)
#We have used tanh as an activation function in this architecture so we will use tanh at all layers excluding F7.
x = self.act(x)
#Now this will be passed from pooling
x = self.pool(x)
#Next stage is convolution
x = self.conv2(x)
x = self.act(x)
x = self.pool(x)
#next we will pass from conv3, here we will not pass data from pooling as per Architecture
x = self.conv3(x)
x = self.act(x)
#Now the data should be flaten and it would be passed from FC layers.
x = x.view(x.size()[0], -1)
x = self.L1(x)
x = self.act(x)
x = self.L2(x)
return x
x = torch.randn(1,1,32,32)
model = LeNet()
summary(model,(1,32,32))
Saya telah menggunakan Arsitektur diatas akan tetapi dengan mengubah ukuran gambar dari 32 menjadi 100 x 100 untuk digunakan gambar yang lainnya. Berikut hasil ketika menggunakan dataset MNIST ukuran 100 x 100
Epoch [0], train_loss: 37.4529, test_loss: 19.0805, test_acc: 0.9551 Epoch [1], train_loss: 16.0223, test_loss: 14.1206, test_acc: 0.9673 Epoch [2], train_loss: 11.5352, test_loss: 12.0725, test_acc: 0.9711 Epoch [3], train_loss: 9.3607, test_loss: 10.7257, test_acc: 0.9741 Epoch [4], train_loss: 7.9092, test_loss: 9.5771, test_acc: 0.9758 Epoch [5], train_loss: 6.4773, test_loss: 9.2016, test_acc: 0.9774 Epoch [6], train_loss: 5.2964, test_loss: 8.1720, test_acc: 0.9786 Epoch [7], train_loss: 4.5144, test_loss: 8.5373, test_acc: 0.9788 Epoch [8], train_loss: 4.2078, test_loss: 8.3574, test_acc: 0.9788 Epoch [9], train_loss: 3.7291, test_loss: 8.3884, test_acc: 0.9787
Sebenarnya cukup mudah untuk me resize ukuran gambar menggunakan transform. Saya menggunakan kode berikut
import torchvision.transforms as transforms
import numpy as np
transform = transforms.Compose(
[
transforms.Resize((100,100)),
transforms.ToTensor()
])
train = datasets.MNIST(root='data',train=True,transform=transform,download=False)
test = datasets.MNIST(root='data',train=False,transform=transform,download=False)
karena ukuran input berubah, maka harus ada yang diubah yaitu
self.L1 = nn.Linear(256, 120)
menjadi
self.L1 = nn.Linear(16*22*22, 120) #untuk ukuran 100*100
Klasifikasi Gambar dengan Arsitektur LeNet
Untuk kasus yang lain saya coba dengan Dataset yang digunakan yaitu untuk melakukan klasifikasi dog dan cat https://www.kaggle.com/c/dogs-vs-cats/data. Berikut hasil klasifikasi yang telah dilakukan learning sebanyak 50 epoch dengan accuracy 97.5%
