
Pada artikel ini kita akan memahami teknik yang disebut Principal Component Analysis (PCA) – analisis komponen utama (AKU) yang digunakan untuk mengurangi dimensi ketika kita memiliki terlalu banyak fitur input karena sebagai manusia kita hanya mampu melihat geometri pada R^3 atau tiga dimensi saja yaitu sumbu X, Y, dan Z. Kita aakan memahami apa itu PCA dan cara kerjanya dengan contoh langkah demi langkah menghitung PCA
Mengapa Pengurangan Dimensi / Feature perlu dilakukan?
Contents
- 1 Mengapa Pengurangan Dimensi / Feature perlu dilakukan?
- 2 PCA menyimpan informasi penting tanpa menghilangkan feature
- 3 Bagaimana PCA bekerja?
- 4 Kita sekarang telah mengubah fitur baru
- 5 Cara cepat menghitung PCA menggunakan Sklearn
- 6 Terus gimana lagi?
- 7 Menggunakan PCA untuk mereduksi dataset iris
- 8 Kasus Lain, Apakah PCA dapat digunakan untuk image processing
- 9 Kesimpulan
Saat kita memiliki dataset dengan beberapa fitur masukan dan menghasilkan model yang overfit maka dibutuhkan pengurangan ruang fitur masukan / mengekstrak fitur.
- Hapus fitur yang tidak relevan dan berlebihan karena tidak berkontribusi pada keakuratan masalah prediksi. Namun ketika kita membuang variabel input seperti itu malahan kita kehilangan informasi yang disimpan dalam variabel ini, maka untuk itu
- Kita dapat membuat variabel independen baru dari variabel input yang ada. Dengan cara ini kita tidak kehilangan informasi dalam variabel sehingga cara ini disebut dengan ekstraksi fitur /feature extraction.
Sebagai gambarannya: jika kita ingin memprediksi penjualan sebuah toko retail untuk Item tertentu. Fitur input yang digunakan untuk prediksi adalah
- angka penjualan,
- perubahan retail Item,
- pergerakan inventaris,
- detail toko,
- retail pesaing,
- demografi pelanggan, dan
- informasi pelanggan seperti alamat, kode pos, dll.
Dari 7 feature input diatas, kita dapat membuang variabel tertentu seperti informasi pelanggan. Itu tidak berkontribusi untuk memprediksi penjualan untuk toko ritel, akan tetapi ketika kita menghapus variabel ini, maka kita akan kehilangan informasi yang tersedia di variabel tersebut.
PCA menyimpan informasi penting tanpa menghilangkan feature
Analisis Komponen Utama -PCA membantu menyimpan informasi penting dalam kumpulan data tanpa menghilangkan fitur. PCA melakukan ini dengan membuat variabel independen baru dari variabel input yang ada.
Saat kita memiliki dataset besar dari variabel input yang berkorelasi dan kita ingin mengurangi jumlah variabel input ke ruang fitur yang lebih kecil dengan tetap mempertahankan informasi penting. Hal ini dapat menyelesaikan ini dengan menggunakan Principal Component Analysis-PCA.
PCA mereduksi dimensi data menggunakan ekstraksi fitur. Ini dilakukan dengan menggunakan variabel yang membantu menjelaskan sebagian besar variabilitas data dalam kumpulan data
PCA menghapus informasi yang berlebihan dengan menghapus fitur terkait. PCA menciptakan variabel independen baru yang independen satu sama lain hal ini berkaitan dengan masalah multikolinearitas.
PCA adalah teknik tanpa pengawasan/ unsupervised karena hanya melihat fitur masukan dan tidak memperhitungkan keluaran atau variabel target.
Tujuan PCA adalah untuk mengurangi dimensi fitur masukan dari dataset dari m ke p dimana p <m dengan tetap mempertahankan semua informasi penting yang ada dalam data dengan dimensi yang dikurangi.
Bagaimana PCA bekerja?
Langkah pertama dalam analisis komponen utama adalah membakukan fitur masukan. Fitur masukan yang berbeda mungkin pada unit yang berbeda. Standarisasi fitur masukan menempatkannya pada skala unit yang sama biasa disebut dengan normalisasi
import numpy as np import pandas as pd from numpy.linalg import eig A =np.array([[100, 1, 1075],[125, 2,1900], [150, 1, 950], [91,1, 1650]]) print(A) mean_A = np.mean(A.T, axis=1, dtype=np.int) print(mean_A)
hasil
output:[[ 100 1 1075]
[ 125 2 1900]
[ 150 1 950]
[ 91 1 1650]]
output: array([ 116, 1, 1393])
Setelah melakukan standarisasi data, kami menemukan korelasi atau kovarian antara variabel yang berbeda. Korelasi menunjukkan jika dua variabel memiliki hubungan. Jika terkait apakah mereka memiliki hubungan positif atau negatif melalui tahapan sebagai berikut
center_A= (A - mean_A) print(center_A)
hasil
output: array([[ -16, 0, -318],
[ 9, 1, 507],
[ 34, 0, -443],
[ -25, 0, 257]])
Dilanjutkan perhitungan covariance
covariance = np.cov(center_A.T)
Dilanjutkan perhitungan vektor eigen dan nilai eigen dengan melakukan dekomposisi eigen menggunakan matriks korelasi. Untuk mengurangi dimensi kita perlu memilih fitur masukan dengan variabilitas maksimum. Nilai eigen menentukan besarnya variabilitas.
Mari kita pahami secara singkat apa itu vektor eigen dan nilai eigen dan bagaimana keduanya membantu kita memahami variabilitas dalam data
Vektor eigen dan nilai eigen
Lihat matriks A yang kita terapkan transformasi linier x sedemikian rupa berikut ini
![\[ y = Ax \]](https://softscients.com/wp-content/ql-cache/quicklatex.com-0840f06149ced01ca515efc7d3ecf311_l3.png "Rendered by QuickLaTeX.com")
Di sini x adalah vektor yang tidak berubah arah seiring dengan transformasi linier tetapi besarnya vektor bervariasi λ sedemikian rupa
![\[Ax= λx\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-7d6e48b2d24341b29422847f8634e586_l3.png "Rendered by QuickLaTeX.com")
dengan λ adalah eigenvalue and x adalah eigenvector.
value, vector = eig(covariance) print(value.astype(int))
hasil
output:[206898 630 0]
kita melihat fitur 1 dan fitur 2 memiliki nilai eigen tertinggi jadi kita perlu menggunakan vektor eigen untuk
- kolom 0 : 206898, dan
- kolom 1 : 630
Kita sekarang telah mengubah fitur baru
Untuk mendapatkan fitur baru menggunakan rumus
![\[PCA = vector^T \cdot \hat{A}^T\]](https://softscients.com/wp-content/ql-cache/quicklatex.com-bc26122a8536c7153fe6c39bb3242563_l3.png "Rendered by QuickLaTeX.com")
vector_with_highest_eigenvalue= vector[:,[0,1]] PCA_calc = vector_with_highest_eigenvalue.T.dot(center_A.T) print(PCA_calc.T)
hasil
output:[[ 317.63555359 -22.07788348]
[-506.73564035 18.70361328]
[ 443.56928479 25.52011189]
[-257.43119689 -20.07930745]]
Kalian bisa melihat dari variabel A yang terdiri dari 4 baris x 3 kolom menjadi hanya 4 baris x 2 kolom saja
A =np.array([[100, 1, 1075],[125, 2,1900], [150, 1, 950], [91,1, 1650]])
menjadi
output:[[ 317.63555359 -22.07788348]
[-506.73564035 18.70361328]
[ 443.56928479 25.52011189]
[-257.43119689 -20.07930745]]
Cara cepat menghitung PCA menggunakan Sklearn
Bila terlalu panjang cara kerja diatas, kita bisa menggunakan library sklearn untuk menghitung nilai PCA
import numpy as np import pandas as pd from sklearn.decomposition import PCA pca= PCA(n_components=2) pca.fit(A) PCA_value= pca.transform(A) print(PCA_value)
Hasil
output:[[-318.3760533 -22.59451704]
[ 505.99514063 18.18697972]
[-444.3097845 25.00347833]
[ 256.69069718 -20.59594101]]
Nilai diataslah yang sering digunakan feature extraction yang bisa digunakan untuk sebagai masukan ke machine learning.
Terus gimana lagi?
Yuk kita coba dengan dataset iris berikut yaitu
- Setosa,
- Versicolour, dan
- Virginica
terdiri dari 150 data dengan masing-masing ada 4 informasi yaitu
- Sepal Length,
- Sepal Width,
- Petal Length, dan
- Petal Width
from sklearn import datasets iris = datasets.load_iris
Kita sebut saja X dan label untuk mempermudah alurnya
X = iris.data labels = iris.target
label akan berisi angka 0 sampai 2 {0,1,2} yang punya arti
- Setosa,
- Versicolour, dan
- Virginica
Kita buat sebuah data frame agar lebih mudah untuk diolah lebih lanjut
jenis = ['Setosa','Versicolour','Virginica']
parameter = ['Sepal Length','Sepal Width','Petal Length','Petal Width']
import pandas as pd
data = pd.DataFrame(data = X,
columns = parameter)
data['label'] = labels
Kita buat juga aturan berikut
targets = [0,1,2] colors=['green', 'blue', 'red'] x = parameter[0] y = parameter[1] z = parameter[2]
parameter[0] maksudnya Sepal Length dan seterusnya, dilanjut kita buat visualisasi sebagai berikut (karena akan sulit bila menggunakan 4 dimensi, sehingga kita hanya mampu 3 dimensi saja
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for target, color in zip(targets,colors):
index = data['label'] == target
ax.scatter(data.loc[index, x],
data.loc[index, y],
data.loc[index, z],
c = color,
s = 50)
ax.legend(jenis)
ax.grid()
ax.set_xlabel(x)
ax.set_ylabel(y)
ax.set_zlabel(z)

saya putar-putar lagi view nya seperti berikut, akan nampak perbedaaanya

Kalau ganti semula {x: sepal length; y: sepal witdh; z: petal length}
x = parameter[0] y = parameter[1] z = parameter[2]
menjadi {x: sepal length; y: sepal witdh; z: petal width}
x = parameter[0] y = parameter[1] z = parameter[3]

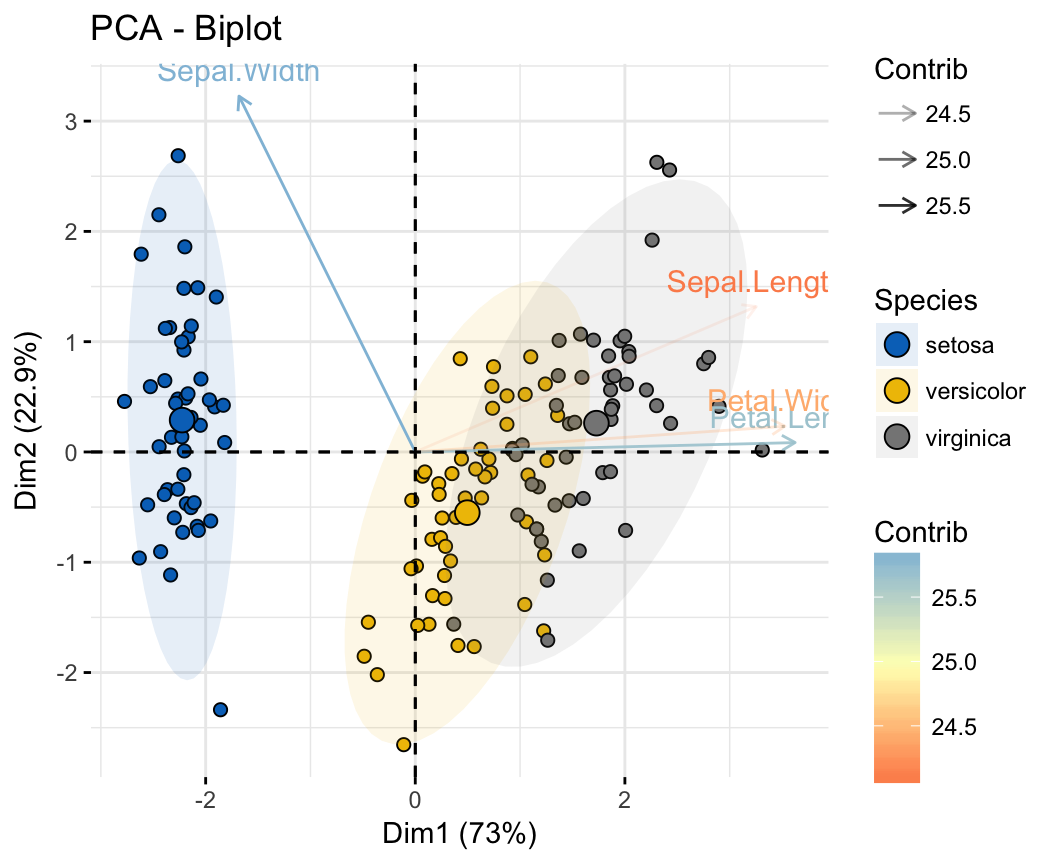
Cukup merepotkan bukan? karena kita harus satu-persatu untuk mengubah sumbu nya mengingat ada 4 paramater yang harus divisualisaskan kedalam 3D jadi nya harus gantian satu persatu. Nah saat nya kita menggunakan PCA untuk mereduksi 4 menjadi 3 saja.
Menggunakan PCA untuk mereduksi dataset iris
Yup, kita gunakan sklearn
from sklearn.decomposition import PCA
import numpy as np
pca = PCA(n_components = 3, svd_solver='full')
pca_results = pca.fit_transform(np.array(X))
parameter_pca = ['pca_1', 'pca_2','pca_3']
pca_df = pd.DataFrame(data = pca_results,
columns = parameter_pca)
pca_df['label'] = labels
targets = [0,1,2]
colors=['green', 'blue', 'red']
x = parameter_pca[0]
y = parameter_pca[1]
z = parameter_pca[2]
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for target, color in zip(targets,colors):
index = pca_df['label'] == target
ax.scatter(pca_df.loc[index, x],
pca_df.loc[index, y],
pca_df.loc[index, z],
c = color,
s = 50)
ax.legend(jenis)
ax.grid()
ax.set_xlabel(x)
ax.set_ylabel(y)
ax.set_zlabel(z)
Hasilnya sebagai berikut (proyeksi linear)

Kalian lanjut pelajari Linear Discriminant Analyst dan tsne – T-distributed Stochastic Neighbor Embedding(t-SNE)
Kasus Lain, Apakah PCA dapat digunakan untuk image processing
Sebuah citra berukuran M x N dapat kita reduksi juga lho, bila kalian baca artikel ini yaitu sebuah citra/image yang punya ukuran 28 x 28 berisi tulisan tangan 0 sampai 9, kita bisa saja melakukan reduksi menjadi ukuran 3 dimensi saja, apakah bisa terlihat lebih baik? Kita coba saja yuk. Oiya pastikan kalian terkoneksi dengan internet karena butuh datasetnya
import time import numpy as np import pandas as pd (X_train, y_train) , (X_test, y_test) = mnist.load_data()
ukuran variabel diatas cukup besar yaitu X_train.shape
(60000, 28, 28)
Artinya ada 60 ribu records dengan masing-masing records punya ukuran dimensi 28 x 28, yuk kita coba saja tampilkan, apakah betul berisi sebuah gambar tulisan tangan menggunakan library matplotlib berikut
from matplotlib import pyplot as plt angka = X_train[800,:,:] plt.figure() plt.imshow(angka,cmap='gray') plt.show()

Ternyata index ke 800, berisi angka 9, kita lanjutkan untuk reduksi saja ke 3 saja dengan kode sebagai berikut, karena ukurannya cukup besar yaitu 60 ribu, ya harap bersabar agar tidak overload memory. Oiya kita reshape dulu donk, untuk mengubah
(60000, 28, 28)
menjadi
(60000, 784)
Kita buat nama variabel baru lagi saja ya
img_cols = 28 #ukuran gambar img_rows = 28 X_train_reshape = X_train.reshape(X_train.shape[0], img_rows*img_cols)
Ok langsung saja, kita akan melakukan Principal Component Analysis -PCA untuk Reduksi Dimensi melalui kode berikut
from sklearn.decomposition import PCA import numpy as np pca = PCA(n_components = 3, svd_solver='full') pca_results = pca.fit_transform(np.array(X_train_reshape))
Yuk kita cek, apakah dimensinya sudah betul
pca_results.shape
hasilnya dari semula 784 berkurang menjadi 3 saja yaitu
(60000, 3)
Saya juga penasaran, apakah PCA yang notabene adalah proyek linear mampu visualisasi dengan baik dari dimensi besar menjadi dimensi kecil? dam…. hasilnya cukup menggembirakan, saya akan rotasi dengan beberapa sudut dan agak lama proses nya karena ada 60 ribu data dalam 3 dimensi (RAM 8 single channel nampaknya kurang begitu cepat)


Selanjutnya? Ya kalian saja yang nerusin mau dibuat apa itu data, misalkan untuk teknik KMeans Clustering, Fuzzy C-Means Clustering atau yang lainnya atau malah buat dibuat LDA lagi.. terserah kalian saja….
Kesimpulan
Salah satu masalah yang sering terjadi dalam suatu machine learning adalah “Curse of Dimensionality problem”, di mana mesin kesulitan dalam menangani sejumlah masukan data dengan dimesi yang sangat tinggi. Salah satu cara yang paling umum digunakan untuk menangani proses ini adalah dengan mengurangi dimensi dari data masukan dengan tetap menjaga informasi yang terkandung didalamnya. Salah satu cara yang paling sering digunakan adalah PCA (Principal Component Analysis), karena PCA dapat mereduksi dimensi seminimal mungkin dengan tetap mempertahankan informasi yang terkandung di dalamnya.
Ref:
https://id.wikipedia.org/wiki/Analisis_komponen_utama
https://scikit-learn.org/stable/modules/decomposition.html
bang yg pake csv gmn caranya, kebanyakan contohnya pake iris, kalo pake file csv bingung
Bang, tolong tuliskan siapa nama penulisnya ini? Saya ingin mensitasi laman ini.
Untuk nama penulisnya
Devi nurtiyasari