

Forecasting Time Series ARIMA – metode ARIMA termasuk perhitungan yang cukup rumit karena menggunakan 3 pendekatan yaitu Auto Regresive, Differencing (integrasi), dan Moving Average. Pada pembahasan sebelumnya Pengertian dan Cara Perhitungan ARIMA serta Prediksi Model ARIMA sudah dijabarkan dengan detail cara perhitungan dan langkah-langkah yang harus diambil mulai dari pengecekan uji stasioner, plot ACF, PACF, serta pengujian signifikansi.
Agar tidak njlimet karena banyak sekali langkah-langkahnya, saya buatkan lagi Contoh Studi Kasus Forecasting Time Series ARIMA yang sederhana dan mengacu hasil pada SPSS.
Hasil ARIMA pada SPSS agak sedikit berbeda dengan R karena beda pengaturan, tapi jangan kuatir kok itu tidak masalah. Misalkan nilai p-value pada R = 0.04 akan tetapi di SPSS = 0.036 akan tetapi nilai tersebut dibawah nilai alpha. Akan lain cerita kalau nilai nya berbeda sangat jauh sehingga menimbulkan perbedaan penarikan kesimpulan.
Contoh Studi Kasus Forecasting Time Series ARIMA dibuag lebih simple karena data tersebut sudah stasioner. Berikut data yang akan digunakan untuk Studi Kasus Forecasting Time Series ARIMA berupa penjualan harian kopi dengan satuan kg.
Data Penjualan Kopi
Contents
Uji Stasioneritas
Walaupun Contoh Studi Kasus Forecasting Time Series ARIMA sudah yakin bersifat stasioner, maka kita pastikan menggunakan Uji Stasioneritas Data dengan adf.test dan nilai lag serta sekalian di plotkan.
library(readxl)
library(lmtest)
library(forecast)
library(ggplot2)
library(tseries)
df = read_xlsx('Data Penjualan Kopi.xlsx')
ggplot(data = df,aes(x=Hari,y=Kuantum))+
geom_line()+
labs(title='Data penjualan kopi')
adf.test(df$Kuantum )
hasil nilai p-value < 0.05 sehingga data tersebut stasioner
Augmented Dickey-Fuller Test data: df$Kuantum Dickey-Fuller = -3.7023, Lag order = 3, p-value = 0.03218 alternative hypothesis: stationary
Kita bisa lihat plot nya

Sehingga nanti d = 0
Plot ACF PACF dan Penduga Model ARIMA
Untuk menduga model ARIMA yang digunakan, kita butuh plot ACF dan PACF nya. Baca lebih lanjut mengenai Korelasi linear Pearson dan Fungsi Autokorelasi (ACF) PACF
acf(df$Kuantum,lag.max = 20) pacf(df$Kuantum,lag.max = 20)


Melalui tabel berikut, kita bisa menduga model ARIMA yang akan gunakan
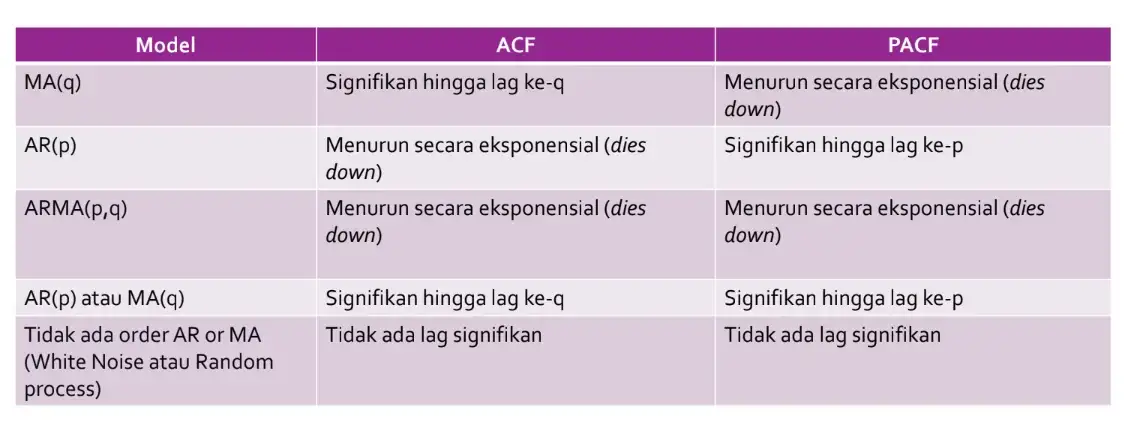
Maka model ARIMA yang mungkin yaitu
- AR(1)
- MA(1) atau
- ARIMA(1,0,1)
Yuk kita hitung saja modelnya
model1 = arima(df$Kuantum,order = c(1,0,0)) model2 = arima(df$Kuantum,order = c(0,0,1)) model3 = arima(df$Kuantum,order = c(1,0,1))
Uji Signifikansi
Agar terlihat lebih jelas, kita uji signifikansi nya saja
lmtest::coeftest(model1) lmtest::coeftest(model2) lmtest::coeftest(model3)
terlihat hasil sebagai berikut
Model1 dengan nilai p-value ar1 = 0.000278 < 0.05 sehingga signifikan
z test of coefficients:
Estimate Std. Error z value Pr(>|z|)
ar1 0.41965 0.11545 3.635 0.000278 ***
intercept 58.08327 0.44446 130.682 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Model2 dengan nilai p-value ma1= 0.001418 < 0.05 sehingga signifikan
z test of coefficients:
Estimate Std. Error z value Pr(>|z|)
ma1 0.37971 0.11900 3.1909 0.001418 **
intercept 58.08456 0.36503 159.1222 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Model3 dengan
- nilai p-value ar1 = 0.01215 < 0.05 sehingga signifikan
- nilai p-value ma1 = 0.46877 > 0.05 sehingga tidak signifikan
z test of coefficients:
Estimate Std. Error z value Pr(>|z|)
ar1 0.58753 0.23428 2.5078 0.01215 *
ma1 -0.20737 0.28623 -0.7245 0.46877
intercept 58.08663 0.49025 118.4842 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Oleh sebab itu Model1 dan Model2 yang akan digunakan karena signifikan. Kemudian kita akan hitung accuracy nya untuk memilih RMSE terkecil
accuracy(model1) accuracy(model2)
hasil
> accuracy(model1)
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.00361766 2.021856 1.646999 -0.1192122 2.866773 0.828836 -0.02782611
> accuracy(model2)
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.0042888 2.058667 1.666808 -0.1243721 2.900867 0.8388048 0.04529846
>
Terlihat RMSE untuk model1 lebih kecil sehingga model arima yang digunakan adalah AR1
Prediksi untuk 10 hari kedepan penjualan harian kopi yaitu hari ke 61 sampai dengan 70
hasil = predict(model1,10) hasil$pred
hasilnya
$pred Time Series: Start = 61 End = 70 Frequency = 1 [1] 57.92744 58.01788 58.05583 58.07175 58.07844 58.08124 58.08242 58.08291 58.08312 58.08321
Kita gabungkan antara data yang lama dengan hasil prediksi dan plotkan hasilnya
hasil.prediksi = data.frame(Hari=c(61:70),Kuantum = hasil$pred) ggplot()+ geom_line(data=df,aes(x=Hari,y=Kuantum))+ geom_line(data=hasil.prediksi,aes(x=Hari,y=Kuantum),color='red')+ labs(title='Data penjualan kopi')
hasilnya
